博客
Tools
apidoc-generator API文档生成器简介
一、概述
基于java源码中的注释(不限于多行或单行)和泛型解析,来生成api文档元数据和具体文档输出的工具
只需要指定想要解析的接口源码目录,并保证接口涉及的所有类都包含在classpath下,然后再设置渲染方式,最后运行便可获得最终结果
目前支持json-with-comment 和 swagger-editor两种输出方式
二、实现原理
@startuml
folder "数据源" {
component [source源码] as src
component [source源码对应的class和依赖] as classpath
}
package "Java源码解析" {
component [Java源码解析 com.github.javaparser] as javaparser
src --> javaparser
}
node "Java类型解析" {
component [类型解析 databind-core] as type
component [数据Mock databind-json] as mock
component [带注释的Json序列化 ] as jwc
classpath --> type
type --> mock
mock --> jwc
}
frame "文档渲染" {
component [API Doc元数据] as doc
component [Markdown] as md
component [Swagger元数据] as sg
javaparser --> doc
type --> doc
doc --> mock
jwc --> md
doc --> md
doc --> sg
}
@enduml
三、接入姿势
3.1 项目侵入式接入
可以编写单元测试或单独的模块来接入
3.1.1 gradle 依赖引入
repositories {
maven { url 'https://oss.sonatype.org/content/repositories/snapshots/' }
}
testImplementation 'org.dreamcat:apidoc-generator:0.1-SNAPSHOT'
3.1.2 maven 依赖引入
<project>
<repository>
<id>snapshots-repo</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases><enabled>false</enabled></releases>
<snapshots><enabled>true</enabled></snapshots>
</repository>
<dependency>
<groupId>org.dreamcat</groupId>
<artifactId>apidoc-generator</artifactId>
<version>0.1-SNAPSHOT</version>
<scope>test</scope>
</dependency>
</project>
3.1.3 单元测试示例
源码样例
public interface ComplexService {
// list complex
ApiResult<ApiPageSummary<ComplexModel, ComplexSummaryModel>> list(ComplexListParam param);
/**
* create complex
*
* @param param require param to create complex
* @param file attachment
* @return complex id
*/
ApiResult<String> create(ComplexCreateParam param, byte[] file);
}
public class ComplexListParam extends PageParam {
private String token; // the token to sign
private Set<Integer> userIds; // users who admire the number
}
单元测试
import java.util.Collections;
import org.dreamcat.cli.generator.apidoc.ApiDocConfig;
import org.dreamcat.cli.generator.apidoc.ApiDocGenerator;
import org.dreamcat.cli.generator.apidoc.renderer.JsonWithCommentRenderer;
import org.junit.jupiter.api.Test;
class JavaDocTest {
@Test
void test() throws Exception {
String srcDir = "/path/to/project/src/main/java";
// 想要分析的Service接口的源码目录
String javaFileDir = srcDir + "/com/example/service";
// 支持源码分析的java基础包名
String basePackage = "com.example";
// API文档生成器的配置
ApiDocConfig config = new ApiDocConfig();
config.setBasePackages(Collections.singletonList(basePackage));
config.setSrcDirs(Collections.singletonList(srcDir));
config.setJavaFileDirs(Collections.singletonList(javaFileDir));
// 第一种输出:设置渲染方式为带注释的Json markdown格式
JsonWithCommentRenderer jsonWithCommentRenderer = new JsonWithCommentRenderer(config);
jsonWithCommentRenderer.setSeqFormatter(i -> "#### 4.1." + i);
ApiDocGenerator<String> markdownGenerator = new ApiDocGenerator<>(config, jsonWithCommentRenderer);
String markdown = markdownGenerator.generate();
System.out.println(markdown);
// 第二种输出:设置渲染方式为swagger-editor yaml格式
SwaggerRenderer swaggerRenderer = new SwaggerRenderer();
swaggerRenderer.setdDfaultTitle("Some Stuff");
ApiDocGenerator<String> yamlGenerator = new ApiDocGenerator<>(config, swaggerRenderer);
String yaml = yamlGenerator.generate();
System.out.println(yaml);
}
}
四、输出姿势
4.1 带注释的Json Markdown文档输出
示例如下
4.1.1 list complex
入参
{
"pageNo": 1616467239, // page number, default is 1
"pageSize": 1187568143, // page size, default is 10
"token": "05Ie60000000", // the token to sign
"userIds": [
1360046618
] // users who admire the number
}
出参
{
"code": "Z14dx00", // response code
"msg": "6d1B", // error message
"data": {
"pageNo": 332708021, // page number, default is 1
"pageSize": 1363282705, // page size, default is 10
"list": [
{
"id": "0HN5X", // /! entity id
"createdBy": 7819338319132650901, // who created the record
"createdAt": "2021-12-20 20:18:56", //
"a": 2114287267, // a or a + bi
"b": 1421927723, // b of a + bi
"salt": [
3
], // salt to sign
"admired": [
{
"id": 6733097960264216561,
"name": "2O9eO000000000",
"gender": female
}
] // * the people who admire the number
}
], // the list data per page
"totalCount": 1593462666, // the total count
"totalPage": 585256653, // the total page
"summary": {
"todayCount": 940383353038686031, // count of today
"last7dayCount": 2958055079033281580, // count of last 7 day
"bits": [
367530979
] // magic bits
} // the summary per page
} // real data
}
4.1.2 create complex
入参
{
"a": 15466019106679717788876966621497800342, // some of complex
"b": 1.14164135352093225954791023656452E+616, // some of complex
"props": {
"Q14iG0000": "VWsEa00000"
} // props for extra settings
}
出参
{
"code": "k", // response code
"msg": "7RwO600", // error message
"data": "OgF6" // real data
}
4.2 Swagger Editor Yaml文档输出
示例如下
---
swagger: "2.0"
info:
version: "1.0.0"
title: "Default Title"
tags:
- name: "com.example.controller.ComplexController"
description: ""
schemes:
- "https"
- "http"
paths:
/api/v1/get:
get:
tags:
- "com.example.controller.ComplexController"
description: "get complex"
operationId: "GET_get"
parameters:
- in: "query"
name: "id"
description: ""
required: true
type: "string"
responses:
"200":
description: "ApiResult<ComplexModel>"
schema:
$ref: "#/definitions/ApiResult_ComplexModel"
definitions:
ApiResult_ComplexModel:
type: "object"
properties:
msg:
type: "string"
data:
type: "object"
properties:
admired:
type: "array"
items:
type: "object"
properties:
name:
type: "string"
gender:
type: "string"
enum:
- "unknown"
- "female"
- "male"
id:
type: "object"
format: "int64"
createdAt:
type: "object"
format: "date-time"
a:
type: "object"
format: "int32"
b:
type: "integer"
format: "int32"
salt:
type: "array"
items:
type: "object"
createdBy:
type: "integer"
format: "int64"
id:
type: "string"
code:
type: "string"
BigData
Flink 简介
概述
Apache Flink是一个开源的分布式,高性能,高可用,准确的流处理框架。同时支持实时流(stream)处理和批(batch)处理,其中批数据看做是流数据的一个特例。
在批(batch)处理中,批数据是在时间上有界的数据,需要处理的数据量是确定的。而在流(stream)处理中,流数据是在时间上无界的数据。相对于批数据,流数据增加了一个新的时间维度。流处理和批处理,需要处理的对象都是大数据,需要解决大数据处理的共性问题。
流处理和批处理
CAP定理是大数据处理的基础约束,对一个分布式计算系统,C(Consistency 一致性)、A(Availability 可用性)、P(Partition tolerance 分区容忍性)难以同时满足。
因为大数据处理是在分布式环境下执行的,所以P是默认要满足的,C和A之间需要做出权衡取舍。
对于批处理系统,追求的是C,保证结果的正确性,牺牲了A,因为批处理对延时不敏感,几分钟甚至几小时之内获得计算结果都可以。
对于流处理系统,首先要保证C,用户对数据处理的基本需求,是要获得正确的结果。但是A也不能牺牲,因为流式数据处理天然有实时性的需求,较高的数据延时会严重影响用户体验。受CAP定理的约束,C和A难以兼得,于是在流式处理系统中,问题被定义成:在保证准确性的前提下,尽可能地追求实时性。
Flink设计思想
@startmindmap
'!theme sketchy
'!theme silver
!theme plain
'!include https://unpkg.com/plantuml-style-c4@latest/core.puml
+ Flink
++ Stratosphere 大数据分析引擎
+++ Meteor,定义执行逻辑,一种将算子视为一等公民的DSL
+++ Sopremo,将Meteor脚本编译为PACT模型\n\
(用于编写分布式数据批处理作业)
+++ PACT,将PACT定义的数据模型转换成Nephele Job Graph
+++ Nephele,Job Graph的执行引擎,将Job Graph调度和切分成Task任务,\n\
并提供调度、执行、资源管理、容错管理、I/O服务等功能;
++ Google开源论文提出的DataFlow/Beam编程模型
+++ 对无界、无序的数据源按数据本身的特征进行窗口计算
+++ 窗口、时间域和水位线
++ 分布式异步快照算法Chandy-Lamport
+++ 使用两阶段提交保存一个全局快照
-- 低延迟
-- 高吞吐
-- Exactly-Once数据一致性
@endmindmap
Flink解决方案
集群架构
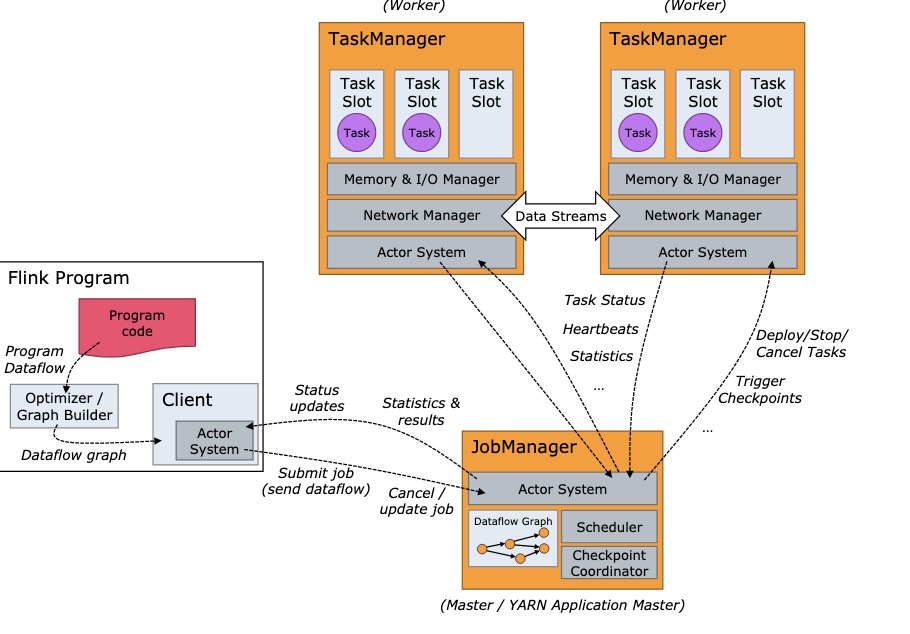
Job提交流程
@startuml
!theme mars
'!theme materia
actor "用户" as user
control "客户端" as client
control "JobManager" as job
control "TaskManager" as task
user -> client: 提交Job\n\
(Table SQL或DataStream API Jar等形式)
client --> client: 加载用户提交的任务代码,\n\
解析成StreamGraph并生成任务执行拓扑图JobGraph
note left
flink内部使用Akka框架(Actor System)和Netty
进行通信, 通过发送消息驱动任务的推进。
end note
client -> job: 将拓扑图JobGraph提交给JobManager
job --> job: 基于任务执行拓扑图JobGraph,\n\
生成相应的物理执行计划ExecutionGraph
job -> task: 将执行计划ExecutionGraph发送给TaskManager执行\n\
(启用Task)
@enduml
JobManager(master)
Flink 系统的管理节点,全局只有一个,管理所有的 TaskManager,并决策用户任务在哪些 Taskmanager 执行。同时在运行过程中,会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
TaskManager (slave)
Flink 系统的业务执行节点,执行具体的用户任务,提供了内存管理、IO管理、网络管理功能。每个TaskManger上运行一个jvm进程。每个TaskManger拥有多个TaskSlot,而每个TaskSlot运行一个线程。Flink允许同一个任务的多个子任务,并且会尽量将多个子任务放到一个slot中执行。
时间
流数据相对于批数据,增加了一个时间维度。时间可以有以下3中表征方式:
Event Time表征事件发生的时间,是事件本身的固有属性,由事件生产者自行定义,默认为空,即Long.MIN_VALUE。可以用于解决消息乱序的时候一致性问题Ingestion Time事件流入Flink source operator的时间。Processing Time事件被Flink算子处理的时间。
@startuml
!theme materia
actor "事件生产者" as producer
note bottom
事件时间
end note
database "消息队列" as mq
frame "Flink" {
collections "source" as source
note bottom
摄入时间
end note
node "TaskSolt 1" as solt1
node "TaskSolt 2" as solt2
note bottom
处理时间
end note
}
producer -right-> mq
mq -right-> source
source -right-> solt1
solt1 -right-> solt2
@enduml
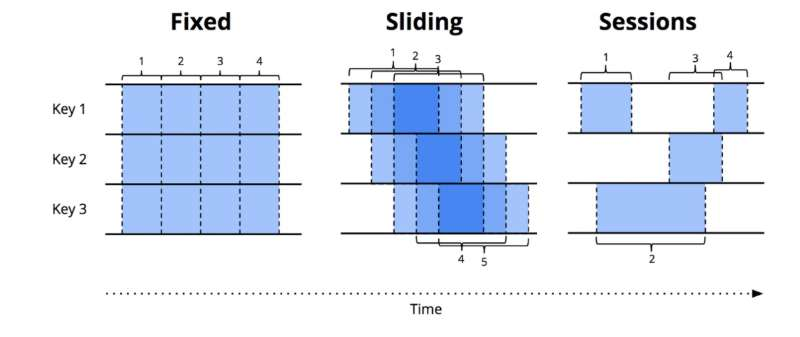
窗口 Window
由于流数据是时间上是无限的,那么可以将数据流在逻辑上做切分,分成一个个的窗口,在每一个窗口中进行数据计算。(这里也可以逐条处理)
Flink 支持以下几种窗口类型:
Tumbling Window: 固定时间间隔的窗口。比如统计每分钟整点内的网站访问次数。Sliding Window: 滑动窗口,按一定的滑动尺寸和窗口大小进行计算。比如统计最近1分钟的网站访问次数,每隔10秒钟输出一次。那么窗口大小为1min,每次滑动前进10s。Sessions Window: 会话窗口。按会话维度进行统计。比如针对每个访问网站的用户建立会话,并且设定会话窗口超时阈值,假设1分钟。如果在最近1分钟之内,用户执行了操作,则将这些操作在同一个会话窗口中进行计算。Custom Window: 自定义窗口,继承WindowAssigner
触发器 Trigger
Flink使用Trigger(触发器)来决定何时输出计算结果。
Repeated update triggers: 这个是最简单的形式,按固定的频率输出计算结果。Completeness triggers: 等到数据完整之后,输出计算结果。如何定义数据完整性呢?这就需要引入Watermark的概念。WaterMark是表征何时数据已经完整的标识。带有时间戳为X的waterMark表示,event time在X之前的数据,已经到齐了。Early/On-Time/Late Triggers: 这个是综合以上两种Trigger,对于早到、准时及迟到的数据分别输出计算结果。实际实现的时候,不会无限制地等待迟到的数据,会加上迟到时间的限制,丢弃超过限制的数据。
水位线 Watermark
Perfect watermarks: 确定性watermark。如果能够准确的评估出数据延迟时间的最大值,就可以使用 perfect watermark。Heuristic watermarks: 启发式watermark。在数据处理的过程中,Flink基于观察到的数据延时,不断的动态调整Watermark的值。适用于数据延时有较大波动的场景。
水位线提供了一种结果可信度和延时之间的妥协。激进的水位线设置可以保证低延迟,但结果的准确性不够;如果水位线设置的过于宽松,计算的结果准确性会很高,但可能会增加流处理程序不必要的延时。在追求数据完整性的过程中,正确性和低延迟不可兼得。我们需要在保证正确性的前提下,尽量减少延迟。如果条件允许的话,最好使用Perfect watermark。
Job 执行流程
每个Job 定义的执行流程都由由以下三个部分组成:
- Source(数据源):负责获取输入数据。
- Transformation(数据处理):对数据进行处理加工,通常对应着多个算子。
- Sink(数据汇):负责输出数据。
Flink程序执行时,由流和转换操作映射到streaming dataflows,每个数据流有一个或多个 source,有一个或多个sink,这个数据流最终形成一个DAG(有向无环图)。
@startuml
!theme mars
database "source" as source
node "transformations" as transformations
database "sink" as sink
source -> transformations
transformations -> sink
@enduml
变换 Transformation
map:输入一个元素,然后返回一个元素flatmap: 输入一个元素,可以返回零个,一个或者多个元素filter: 对流进行过滤,符合条件的数据会被留下keyBy: 根据指定的key进行分组,类似于SQL中的group byreduce: 对数据进行聚合操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值aggregations:sum,min,max等union:合并多个流,新得到的流会包含被合并的流中的所有数据split:根据规则把一个数据流切分为多个流,类似于Java Stream API中的partition
状态 State
Flink中的持久化模型,实现为RocksDB本地文件+异步HDFS持久化,也可使用基于Niagara的分布式存储。
State分为两类:
KeyedState:这里面的key是我们在SQL语句中对应的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段组成的Row的字节数组,每一个key都有一个属于自己的State,key与key之间的State是不可见的;OperatorState:Blink内部的Source Connector的实现中就会用OperatorState来记录source数据读取的offset。
双流inner join场景
@startuml
!theme mars
database "左表 stream" as left
database "右表 stream" as right
queue "Join stream" as join
database "State状态后端" as state
queue "下游 stream" as output
left -> join: 先流入 1,2,3 三个事件
join -> state: 存入 1,2,3
right -> join: 流入 a 一个事件
join -> state: 存入 a
join -> join: 将 a 与左表已经到达的事件 1,2,3 进行join
join -> output: 将join的结果输出到下游
left -> join: 流入 4 一个事件
join -> join: 将 4 与右表已经到达的事件 a 进行join
join -> output: 将join的结果输出到下游
@enduml
定时器服务 TimerService
Flink开箱即用的提供了一套定时触发API,一般在KeyedProcessFunction中使用
void registerEventTimeTimer(long time);注册定时器void deleteEventTimeTimer(long time);删除定时器void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out)自定义回调函数
API示例
DataStream示例代码
public class StreamGraphSimpleDemo {
public static void main(String[] args) throws Exception {
// 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
// 添加输入源 [2, 3, 5, 7, 11]
DataStream<Integer> source1 = env.addSource(new Beep<>(
Arrays.asList(2, 3, 5, 7, 11), 1000L, 10_000L),
"source1", TypeInformation.of(Integer.class));
// 添加另一个输入源 [1.0, 2.0, 3.0, 4.0, 5.0]
DataStream<Double> source2 = env.addSource(new Beep<>(
Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0), 1000L, 10_000L),
"source2", TypeInformation.of(Double.class));
// 双流join [4, 9, 25]
DataStream<Integer> ds1 = source1.join(source2)
// source1 join source2 on source1.a == source2.b
.where(a -> a).equalTo(Double::intValue)
// 开窗,滑动窗口,窗口大小为3s,每次前进1s
.window(SlidingEventTimeWindows.of(Time.seconds(3), Time.seconds(1)))
// 纵向合并
.apply((a, b) -> a * b.intValue(), TypeInformation.of(Integer.class));
// 消息变换,一到一映射 [3, 8, 24]
DataStream<Long> ds2 = ds1
.map(value -> value - 1L);
// 消息变换,一到多映射 [3, 3, 8, 8, 24, 24]
DataStream<Integer> ds3 = ds2
.flatMap(((value, out) -> {
out.collect(value.intValue());
out.collect(value.intValue());
}));
// 分组,类似于SQL中的group by [(3, 3), (8, 8, 24, 24)]
DataStream<String> ds4 = ds3
.keyBy(value -> value % 2 == 0)
// 使用 ProcessFunction 处理每条消息 [-3, -3, +8, +8, +24, +24]
// 与map等算子的区别,在于 ProcessFunction
// 可以访问时间戳,watermark和定时器等
.process(new KeyedProcessFunction<Boolean, Integer, String>() {
@Override
public void processElement(Integer value,
KeyedProcessFunction<Boolean, Integer, String>.Context ctx,
Collector<String> out) throws Exception {
Boolean key = ctx.getCurrentKey();
String sign = key ? "+" : "-";
out.collect(sign + value);
}
});
// 使用 PrintSinkFunction 进行sink输出,即输出到控制台
ds4.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
log.info("sink to console: {}", value);
}
}).name("sink");
env.execute("StreamGraphDemo");
}
@RequiredArgsConstructor
public static class Beep<T> extends RichSourceFunction<T> {
final List<T> list;
final long elementIntervalMs;
final long listIntervalMs;
volatile boolean flag = true;
@Override
public void run(SourceContext<T> ctx) throws Exception {
while (flag) {
for (T element : list) {
ctx.collectWithTimestamp(element, System.currentTimeMillis());
Thread.sleep(elementIntervalMs);
}
ctx.markAsTemporarilyIdle();
Thread.sleep(listIntervalMs);
}
}
@Override
public void cancel() {
flag = false;
}
}
}
代码和DAG的对照
@startuml
!theme mars
queue "消息队列1" as mq1
queue "消息队列2" as mq2
collections "source1" as source1
note top
var env = StreamExecutionEnvironment.getExecutionEnvironment();
SourceFunction<Integer> sourceFunction1 = ...; // 输入源
env.addSource(sourceFunction1); // 添加输入源
end note
collections "source2" as source2
note right
// 另一个输入源
SourceFunction<Double> sourceFunction2 = ...;
// 添加另一个输入源
env.addSource(sourceFunction2);
end note
mq1 -right-> source1
mq2 -down-> source2
node "双流join" as join
note right
DataStream<Integer> ds1 = source1.join(source2)
// on 条件
.where(a -> a).equalTo(Double::intValue)
// 开窗,滑动窗口,窗口大小为3s,每次前进1s
.window(SlidingEventTimeWindows.of(Time.seconds(3), Time.seconds(1)))
// 纵向合并
.apply((a, b) -> a * b.intValue(), TypeInformation.of(Integer.class));
end note
source1 -down-> join
source2 -down-> join
node "Map" as map
note left
DataStream<Long> ds2 = ds1
.map(value -> value - 1L);
end note
join -down-> map
node "FlatMap" as flatMap
note right
DataStream<Integer> ds3 = ds2
.flatMap(((value, out) -> {
out.collect(value.intValue());
out.collect(value.intValue());
}));
end note
map -down-> flatMap
node "KeyedProcess" as keyedProcess
note left
KeyedProcessFunction<K, I, O> keyedProcessFunction = ... ;
DataStream<String> ds4 = ds3
.keyBy(value -> value % 2 == 0)
// 使用 ProcessFunction 处理每条分完组之后的事件
// 与map等算子的区别,在于 ProcessFunction
// 可以访问时间戳,watermark和定时器等
.process(keyedProcessFunction);
end note
flatMap -down-> keyedProcess
collections "sink" as sink
note right
SinkFunction<String> sinkFunction = ...; // sink输出
ds4.addSink(sinkFunction); // 添加sink输出
end note
keyedProcess -down-> sink
@enduml
StreamGraph拓扑图
@startuml
!theme mars
database "Source: source1" as source1
database "Source: source2" as source2
cloud "Map-3" as map1
cloud "Map-4" as map2
node "Window" as win
cloud "Map-8" as map3
cloud "Flat Map" as flatMap
cloud "KeyedProcess" as KeyedProcess
database "Sink: sink" as sink
source1 --> map1: Source: source1_Map-3_0_FORWARD
source2 --> map2: Source: source2_Map-4_0_FORWARD
map1 --> win: Map-3_Window(SlidingEventTimeWindows(3000, 1000), \n\
EventTimeTrigger, \nCoGroupWindowFunction)-7_0_HASH
map2 --> win: Map-4_Window(SlidingEventTimeWindows(3000, 1000), \n\
EventTimeTrigger, \nCoGroupWindowFunction)-7_0_HASH
win --> map3: Window(SlidingEventTimeWindows(3000, 1000),\n\
EventTimeTrigger, \nCoGroupWindowFunction)-7_Map-8_0_FORWARD
map3 --> flatMap: Map-8_Flat Map-9_0_FORWARD
flatMap --> KeyedProcess: Flat Map-9_KeyedProcess-11_0_HASH
KeyedProcess --> sink: KeyedProcess-11_Sink: sink-12_0_FORWARD
@enduml
Flink SQL示例
-- source
-- 骑手轨迹
create table knight_active_trace_kafka_source
(
id varchar
,target_type varchar
,target_id varchar
,longitude varchar
,latitude varchar
,tracked_at varchar
,created_at varchar
,updated_at timestamp
-- 该watermarker5秒之前的数据丢弃
,watermark wk for updated_at as withOffset(updated_at, 5000)
)with(
type='kafka'
,topic='knight_active_trace'
);
-- transformations
create view knight_active_trace_last as
select
target_id as delivery_id,
last_value(date_format(updated_at, 'yyyy-MM-dd HH:mm:ss')) as trace_time
from
knight_active_trace_kafka_source
where
target_type = '2' -- 众包
group by
-- 设置滚动窗口为5分钟
tumble(updated_at, interval '5' minute), target_id
-- sink
insert into result_test
select xxx from xxx;
;
Flink 原理
流量控制
基于Credit的反压机制
下游的InputChannel从上游的ResultPartition接收数据的时候,会基于当前已经缓存的数据量,以及可申请到的LocalBufferPool与NetworkBufferPool,计算出一个Credit值返回给上游。上游基于Credit的值,来决定发送多少数据。Credit就像信用卡额度一样,不能超支
当下游发生数据拥塞时,Credit减少值为0,于是上游停止数据发送。拥塞压力不断向上游传导,形成反压
系统容错
流计算容错一致性保证有三种,分别是:
- Exactly-once,是指每条 event 会且只会对 state 产生一次影响,这里的“一次”并非端到端的严格一次,而是指在 Flink 内部只处理一次,不包括 source和 sink 的处理
- At-least-once,是指每条 event 会对 state 产生最少一次影响,也就是存在重复处理的可能
- At-most-once,是指每条 event 会对 state 产生最多一次影响,就是状态可能会在出错时丢失
Checkpointing检查点
Flink会在流上定期产生一个barrier(屏障)。barrier 是一个轻量的,用于标记stream顺序的数据结构。barrier被插入到数据流中,作为数据流的一部分和数据一起向下流动,过程如下:
- barrier 由source节点发出
- barrier会将流上event切分到不同的checkpoint中
- 汇聚到当前节点的多流的barrier要对齐(At least once不需要对齐)
- barrier对齐之后会进行Checkpointing,生成snapshot,快照保存到StateBackend中
- 完成snapshot之后向下游发出barrier,继续直到Sink节点
Flink 调优
Group Aggregate
开启 MicroBatch/MiniBatch (牺牲延迟以提升吞吐)
缓存一定的数据后再触发处理,以减少对 state 的访问从而显著提升吞吐,以及减少输出数据量
MiniBatch主要依靠在每个 task 上注册的 timer 线程来触发微批,会有一定的线程调度开销。MicroBatch 是 MiniBatch 的升级版,主要基于事件消息来触发微批,事件消息会按用户指定的时间间隔在源头插入。MicroBatch 在攒批效率、反压表现、吞吐和延迟性能上都要胜于MiniBatch
开启 LocalGlobal (解决常见数据热点问题)
适用于提升如 SUM, COUNT, MAX, MIN, AVG 等普通 agg 上的性能,以及解决这些场景下的数据热点问题
将原先的 Aggregate 分成Local+Global 两阶段聚合。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator),第二阶段再将收到的 Accumulator merge起来,得到最终的结果(globalAgg)
TopN
分组 TopN:根据不同的分组进行排序,计算出每个分组的一个排行榜
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]
最优的流式 TopN 的计算只需要维护一个 N 元素大小的小根堆,每当有数据到达时,只需要与堆顶元素比较,如果比堆顶元素还小,则直接丢弃;如果比堆顶元素大,则更新小根堆,并输出更新后的排行榜
TopN 算子的实现上主要有两个数据结构,一个是 TreeMap,另一个是 MapState。TreeMap作为小根堆,有序地存放了排名前 N 的元素。MapState用于持久化TreeMap
嵌套 TopN 解决热点问题
数据倾斜(最坏的情况是全局 TopN,所有数据都倾斜到一个节点)
两层 TopN。在原先的 TopN 前面,再加一层 TopN,用于分散热点
CREATE VIEW tmp_topn AS
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY HASH_CODE(shop_id)%128 ORDER BY sales DESC) AS rownum
FROM shop_sales)
WHERE rownum <= 10
SELECT *
FROM (
SELECT shop_id, shop_name, sales,
ROW_NUMBER() OVER (ORDER BY sales DESC) AS rownum
FROM tmp_topn)
WHERE rownum <= 10
Java
G1 GC 算法
八股文
一、基础篇
网络基础
TCP/IP
三次握手过程(两次握手只能保证单向连接是畅通的):
客户端——发送带有SYN标志的数据包,客户端进入syn_sent状态
服务端——发送带有SYN/ACK标志的数据包,服务端进入syn_rcvd
客户端——发送带有ACK标志的数据包,连接就进入established状态
四次挥手过程(可单向关闭):
客户端——发送FIN数据包,关闭与服务端的连接,进入FIN_WAIT_1状态
服务端–收到这个FIN,发回ACK报⽂确认,进入CLOSE_WAIT状态
服务端——发送FIN数据包,关闭与客户端的连接,进入FIN-WAIT-2状态
客户端–收到这个FIN,发回ACK报⽂确认,进入TIME_WAIT状态
netstat -an | grep TIME_WAIT | wc -l 查看连接数等待time_wait状态连接数
OSI与TCP/IP 模型
- OSI七层:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 - TCP/IP五层:物理层、数据链路层、网络层、传输层、应用层
常见网络服务分层
- 应用层:HTTP、SMTP、DNS、FTP - 传输层:TCP 、UDP - 网络层:ICMP 、IP、路由器、防火墙 - 数据链路层:网卡、网桥、交换机 - 物理层:中继器、集线器
TCP与UDP区别及场景
| 类型 | 特点 | 性能 | 应用场景 | 首部字节 | 应用层协议 |
|---|---|---|---|---|---|
| TCP | 面向连接、可靠、字节流 | 传输效率慢、所需资源多 | 文件、邮件传输 | 20-60 | HTTP、FTP、SMTP |
| UDP | 无连接、不可靠、数据报文段 | 传输效率快、所需资源少 | 语音、视频、直播 | 8 | RIP、DNS、SNMP |
TCP滑动窗口,拥塞控制
TCP通过应用数据分割、对数据包进行编号、校验和、流量控制、拥塞控制、超时重传等措施保证数据的可靠传输
拥塞控制目的:为了防止过多的数据注入到网络中,避免网络中的路由器、链路过载
拥塞控制过程:TCP维护一个拥塞窗口,该窗口随着网络拥塞程度动态变化,通过慢开始、拥塞避免等算法减少网络拥塞的发生
TCP粘包原因和解决方法
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,
发送方原因:TCP默认使用Nagle算法(主要作用:减少网络中报文段的数量),收集多个小分组,在一个确认到来时一起发送
接收方原因:TCP将接收到的数据包保存在接收缓存里,如果TCP接收数据包到缓存的速度大于应用程序从缓存中读取数据包的速度,多个包就会被缓存,应用程序就有可能读取到多个首尾相接粘到一起的包
解决粘包问题:
- 发送定长包
- 包尾加上\r\n标记(FTP协议正是这么做的)
- 包头加上包体长度。包头是定长的4个字节
TCP报文格式
- 源端口号 16 目的端口号 16:用于寻找发端和收端应用进程,这两个值加上ip首部源端ip地址和目的端ip地址唯一确定一个tcp连接
- 序号 32:该连接的初始序号ISN(Initial Sequence Number)
- 确认号 32:上次已成功收到的序号加1,设置ACK标志时有效(建立起来的TCP连接总会设置ACK)
- 首都长度 4 保留 6 标志 6:可选的首都长度(最多60B,没有可选字段时20B),标志有URG紧急指针、ACK确认号、PSH接收方应该尽快将这个报文段交给应用层、RST重建连接、SYN同步序号、FIN关闭连接
- 窗口 16:接收端期望接收的字节,最大为 16KB
- 检验和 16:整个报文段的检验和
- 紧急指针 16:正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号
- 可选的选项:最常见的可选字段是最长报文大小,MSS (Maximum Segment Size)。通常在建立连接的第一个报文段中指明这个选项,指明本端所能接收的最大长度的报文段
- 填充:尾部填充,使最终长度为32的倍数
UDP报文格式
- 源端口号 16 目的端口号 16
- 长度 16:整个报文段的字节长度,最小值为8B(即UDP数据部分为空)
- 检验和 16:整个报文段的检验和
IP报文格式
- 版本 4:IPV4协议版本号4
- 首部长度 4:首部长度指的是首部占32bit字的数目,最长为60B
- 服务类型(TOS)8:包括一个3bit的优先权字段,4bit的TOS子字段和1bit未用位(必须置0)。4bit的TOS分别代表:最小时延、最大吞吐量、最高可靠性和最小费用,只能置其中1比特
- 总长度 16:整个IP数据报的长度,以字节为单位,所以IP数据报最长可达16KB
- 标识字段 16:唯一地标识主机发送的每一份数据报,通常每发送一份报文它的值就会加1
- 标识 3:
- 片偏移 13:
- 生存时间TTL 8:生存时间字段设置了数据报可以经过的最多路由器数。它指定了数据报的生存时间。TTL的初始值由源主机设置(通常为 32或64),一旦经过一个处理它的路由器,它的值就减去1。当该字段的值为 0时,数据报就被丢弃,并发送 ICMP 报文通知源主机
- 协议 8:
- 首部校验和 16:根据IP首部计算的检验和码
- 源IP地址 32 目标IP地址 32:
- 可选的选项:
- ****:
- ****:
HTTP
HTTP2.0
- HTTP1.0:服务器处理完成后立即断开TCP连接
- HTTP1.1:KeepAlived长连接避免了连接建立和释放的开销;通过Content-Length来判断当前请求数据是否已经全部接受
- HTTP2.0:引入二进制数据帧和流(二进制格式)的概念,其中帧对数据进行顺序标识;因为有了序列,服务器可以并行的传输数据
http1.1和http2.0的主要区别: 1、新的传输格式:2.0使用二进制格式,1.x依然使用基于文本格式 2、多路复用:连接共享,不同的request可以使用同一个连接传输(最后根据每个request上的id号组合成正常的请求) 3、header压缩:由于1.x中header带有大量的信息,并且得重复传输,2.0使用encoder来减少需要传输的hearder大小 4、服务端推送:同google的SPDUY(1.x的一种升级)一样
HTTPS
1. 首先客户端先给服务器发送一个请求 2. 服务器发送一个SSL证书给客户端,内容包括:证书的发布机构、有效期、所有者、签名以及公钥 3. 客户端对发来的公钥进行真伪校验,校验为真则使用公钥对对称加密算法以及对称密钥进行加密 4. 服务器端使用私钥进行解密并使用对称密钥加密确认信息发送给客户端 5. 随后客户端和服务端就使用对称密钥进行信息传输
Get和Post区别:GET能被缓存,数据长度受限为2kb
Cookie和Session区别:都是用来跟踪浏览器用户身份的会话方式;Cookie 数据保存在客户端,Session 数据保存在服务器端; Cookie⼀般⽤来保存⽤户信息,Session 的主要作⽤就是通过服务端记录⽤户的状态
操作系统基础
进程和线程
进程:是资源分配的最小单位,一个进程可以有多个线程,多个线程共享进程的堆和方法区资源,不共享栈、程序计数器
线程:是任务调度和执行的最小单位,线程并行执行存在资源竞争和上下文切换的问题
协程:
进程间通信方式IPC
- 管道pipe:亲缘关系使用匿名管道,非亲缘关系使用命名管道,管道遵循FIFO,半双工,数据只能单向通信
- 信号:比如用户调用kill命令将信号发送给其他进程
- 消息队列:
- 共享内存(Share Memory):多个进程直接读写同一块内存空间,需要依靠某种同步机制(如信号量)来达到进程间的同步及互斥
- 信号量(Semaphores):计数器,⽤于多进程对共享数据的访问,这种通信⽅式主要⽤于解决与同步相关的问题并避免竞争条件
- 套接字(Sockets):⽤套接字中的相关函数来完成通信过程
用户态和核心态
用户态:只能受限的访问内存,运行所有的应用程序 核心态:运行操作系统程序,cpu可以访问内存的所有数据,包括外围设备
由于需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络
用户态切换到内核态的3种方式:
- 系统调用:系统中断
- 异常: 当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,比如缺页异常,这时会触发切换内核态处理异常
- 外围设备的中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会由用户态到内核态的切换
内存管理
分段管理: 将程序的地址空间划分为若干段(segment),如代码段,数据段,堆栈段;这样每个进程有一个二维地址空间,相互独立,互不干扰。段式管理的优点是:没有内碎片(因为段大小可变,改变段大小来消除内碎片)。但段换入换出时,会产生外碎片(比如4k的段换5k的段,会产生1k的外碎片)
分页管理: 在页式存储管理中,将程序的逻辑地址划分为固定大小的页(page),而物理内存划分为同样大小的页框,程序加载时,可以将任意一页放入内存中任意一个页框,这些页框不必连续,从而实现了离散分离。页式存储管理的优点是:没有外碎片(因为页的大小固定),但会产生内碎片(一个页可能填充不满)
段页式管理: 段⻚式管理机制结合了段式管理和⻚式管理的优点。简单来说段⻚式管理机制就是把主存先分成若⼲段,每个段⼜分成若⼲⻚,也就是说 段⻚式管理机制 中段与段之间以及段的内部的都是离散的
页面置换算法
置换算法:先进先出FIFO、最近最久未使用LRU、最佳置换算法OPT
- 先进先出FIFO:没有考虑到实际的页面使用频率,性能差、与通常页面使用的规则不符合
- 最近最久未使用LRU:考虑到了程序访问的时间局部性,有较好的性能
- 最佳置换算法OPT:每次选择当前物理块中的页面在未来长时间不被访问的或未来不再使用的页面进行淘汰,实际上无法实现(没办法预知未来的页面)
死锁
死锁条件:
- 互斥条件:进程对所分配到的资源不允许其他进程访问,若其他进程访问该资源,只能等待至占有该资源的进程释放该资源 - 请求与保持条件:进程获得一定的资源后,又对其他资源发出请求,阻塞过程中不会释放自己已经占有的资源 - 非剥夺条件:进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用后自己释放 - 循环等待条件:系统中若干进程组成环路,环路中每个进程都在等待相邻进程占用的资源
解决方法:破坏死锁的任意一条件,比如乐观锁(互斥条件)、资源一次性分配(请求与保持条件)、可剥夺资源(非剥夺条件),资源有序分配(循环等待条件)
多线程基础
线程调度
线程是cpu任务调度的最小执行单位,每个线程拥有自己独立的程序计数器、虚拟机栈、本地方法栈
线程状态:创建、就绪、运行、阻塞、死亡
线程池
通过复用已创建的线程,降低资源损耗、线程可以直接处理队列中的任务加快响应速度、同时便于统一监控和管理
线程池大小设置
- CPU 密集型(n+1)
- IO 密集型(2*n)
Java基础
面向对象三大特性:封装、继承、多态
虚拟机栈中会存放当前方法调用的栈帧(局部变量表、操作栈、动态连接 、返回地址)。多态的实现过程,就是方法调用动态分派的过程,如果子类覆盖了父类的方法,则在多态调用中,动态绑定过程会首先确定实际类型是子类,从而先搜索到子类中的方法。这个过程便是方法覆盖的本质。
集合遍历快速和安全失败
fail—fast 快速失败:当异常产生时,直接抛出异常,程序终止 fail—safe:安全失败:采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改
ThreadLocal
将变量放在当前线程的 ThreadLocalMap 中,以ThreadLocal的弱引用WeakReference<ThreadLocal<?>>为key
该引用在下一次垃圾回收的时候必然会被清理掉,从而会出现 key 为 null 的 value,此时线程长时间不被销毁,可能会产⽣内存泄露(value不会被回收)
使⽤完ThreadLocal ⽅法后,⼿动调⽤ remove() ⽅法可避免上述问题
二、JVM篇
内存模型
Java 内存模型(Java Memory Model,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了 Java 程序在各种平台下对内存的访问都能保证效果一致的机制及规范
volatile
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏)
- 1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面
- 2)它会强制将对缓存的修改操作立即写入主存
- 3)如果是写操作,它会导致其他CPU中对应的缓存行无效
JVM内存
虚拟机栈
局部变量表:局部变量表是一组变量值存储空间,用来存放方法参数、方法内部定义的局部变量。底层是变量槽(variable slot)
操作数栈:是用来记录一个方法在执行的过程中,字节码指令向操作数栈中进行入栈和出栈的过程。大小在编译的时候已经确定了,当一个方法刚开始执行的时候,操作数栈中是空发的,在方法执行的过程中会有各种字节码指令往操作数栈中入栈和出栈。
动态链接:因为字节码文件中有很多符号的引用,这些符号引用一部分会在类加载的解析阶段或第一次使用的时候转化成直接引用,这种称为静态解析;另一部分会在运行期间转化为直接引用,称为动态链接。
返回地址(returnAddress):类型(指向了一条字节码指令的地址)
对象引用
普通的对象引用关系就是强引用。
软引用用于维护一些可有可无的对象。只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。
弱引用对象相比软引用来说,要更加无用一些,它拥有更短的生命周期,当 JVM 进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。
虚引用是一种形同虚设的引用,在现实场景中用的不是很多,它主要用来跟踪对象被垃圾回收的活动。
类加载:加载、验证、准备、解析、初始化
加载阶段: 1.通过一个类的全限定名来获取定义此类的二进制字节流。 2.将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。 3.在Java堆中生成一个代表这个类的java.lang.class对象,作为方法区这些数据的访问入口
验证阶段: 1.文件格式验证(是否符合Class文件格式的规范,并且能被当前版本的虚拟机处理) 2.元数据验证(对字节码描述的信息进行语意分析,以保证其描述的信息符合Java语言规范要求) 3.字节码验证(保证被校验类的方法在运行时不会做出危害虚拟机安全的行为) 4.符号引用验证(虚拟机将符号引用转化为直接引用时,解析阶段中发生)
准备阶段: 准备阶段是正式为类变量分配内存并设置类变量初始值的阶段。将对象初始化为“零”值
解析阶段: 解析阶段时虚拟机将常量池内的符号引用替换为直接引用的过程。
初始化阶段: 执行类中定义的Java程序代码
GC
- MinorGC 在年轻代空间不足的时候发生,
- MajorGC 指的是老年代的 GC,出现 MajorGC 一般经常伴有 MinorGC。
- FullGC 当老年代无法再分配内存或元空间不足的时候等
CMS JDK8
一种年老代垃圾收集器,使用标记-清除算法,关注最短垃圾回收停顿时间,但是会导致⼤量空间碎⽚产⽣
初始标记:只是标记一下 GC Roots 能直接关联的对象,速度很快,STW 并发标记:进行 ReferenceChains跟踪的过程,和用户线程一起工作,不需要暂停工作线程 重新标记:为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,STW 并发清除:清除 GC Roots 不可达对象,和用户线程一起工作,不需要暂停工作线程
G1 JDK9
基于标记-整理算法,精准控制停顿时间,区域划分和优先级区域回收机制
初始标记:STW,仅使用一条初始标记线程对GC Roots关联的对象进行标记 并发标记:使用一条标记线程与用户线程并发执行。此过程进行可达性分析,速度很慢 最终标记:STW,使用多条标记线程并发执行 筛选回收:STW,回收废弃对象,并使用多条筛选回收线程并发执行
ZGC JDK11
染色指针,读屏障,在不关注容量的情况获取最小停顿时间5TB/10ms
JVM性能调优
堆空间设置成操作系统的 2/3,超过 8GB 的堆,优先选用 G1 借用 GCeasy 这样的日志分析工具,定位问题
故障排查
第一步是隔离(把机器从请求列表里摘除),第二步是保留现场,第三步问题排查
# 系统当前网络连接
ss -antp > $DUMP_DIR/ss.dump 2>&1
# 网络状态统计
netstat -s > $DUMP_DIR/netstat-s.dump 2>&1
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1
# 进程资源
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump
# CPU 资源
mpstat > $DUMP_DIR/mpstat.dump 2>&1
vmstat 1 3 > $DUMP_DIR/vmstat.dump 2>&1
sar -p ALL > $DUMP_DIR/sar-cpu.dump 2>&1
uptime > $DUMP_DIR/uptime.dump 2>&1
# I/O 资源
iostat -x > $DUMP_DIR/iostat.dump 2>&1
# 内存
free -h > $DUMP_DIR/free.dump 2>&1
# 进程
ps -ef > $DUMP_DIR/ps.dump 2>&1
dmesg > $DUMP_DIR/dmesg.dump 2>&1
sysctl -a > $DUMP_DIR/sysctl.dump 2>&1
# JVM进程快照
jinfo $PID > $DUMP_DIR/jinfo.dump 2>&1
# JVM运行时的状态信息,包括内存状态、垃圾回收
jstat -gcutil $PID > $DUMP_DIR/jstat-gcutil.dump 2>&1
jstat -gccapacity $PID > $DUMP_DIR/jstat-gccapacity.dump 2>&1
# JVM堆信息
jmap $PID > $DUMP_DIR/jmap.dump 2>&1
jmap -heap $PID > $DUMP_DIR/jmap-heap.dump 2>&1
jmap -histo $PID > $DUMP_DIR/jmap-histo.dump 2>&1
jmap -dump:format=b,file=$DUMP_DIR/heap.bin $PID > /dev/null 2>&1
# JVM 执行栈
jstack $PID > $DUMP_DIR/jstack.dump 2>&1
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1
# Java 进程几乎不响应时候的替补
kill -3 $PID # 打印 jstack 的 trace 信息
gcore -o $DUMP_DIR/core $PID # jmap替补
jhsdb jmap --exe java --core $DUMP_DIR/core --binaryheap # 利用gcore文件生成dump文件
三、MySQL篇
NoSQL
- 列存储 Hbase
- KV存储 Redis
- 图存储 Neo4j
- 文档存储 MongoDB
事务
MySQL的存储引擎InnoDB使用重做日志保证一致性与持久性,回滚日志保证原子性,使用各种锁来保证隔离性
读未提交:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 读已提交:允许读取并发事务已经提交的数据,可以阻⽌脏读,但是幻读或不可重复读仍有可能发⽣ 可重复读:同⼀字段的多次读取结果都是⼀致的,除⾮数据是被本身事务⾃⼰所修改,可以阻⽌脏读和不可重复读,会有幻读 串行化:最⾼的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执⾏,这样事务之间就完全不可能产⽣⼲扰
行锁,表锁,意向锁
InnoDB按照不同的分类的锁: - 共享/排它锁(Shared and Exclusive Locks):行级别锁 - 意向锁(Intention Locks),表级别锁 - 间隙锁(Gap Locks),锁定记录的范围,不包含索引项本身,其他事务不能在锁范围内插入数据。 - 记录锁(Record Locks),对索引项加锁,锁定符合条件的行
Next-key Lock:锁定索引项本身和索引范围。即Record Lock和Gap Lock的结合。可解决幻读问题
MVCC多版本并发控制
InnoDB的MVCC,是通过在每行记录后面保存系统版本号(可以理解为事务的ID),每开始一个新的事务,系统版本号就会自动递增,事务开始时刻的系统版本号会作为事务的ID。这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的,防止幻读的产生
索引
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据(主键索引)
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置(辅助索引)
哈希索引
散列的分布方式,不支持范围查找和排序的功能
B+树索引
B+树是B树的升级版,B+树只有叶节点存放数据,其余节点用来索引。索引节点可以全部加入内存,增加查询效率,叶子节点可以做双向链表,从而提高范围查找的效率,增加的索引的范围
调优
索引优化: - ①最左前缀索引:like只用于’string%’,语句中的=和in会动态调整顺序 - ②唯一索引:唯一键区分度在0.1以上 - ③无法使用索引:!= 、is null 、 or、>< 、(5.7以后根据数量自动判定)in 、not in - ④联合索引:避免select * ,查询列使用覆盖索引
语句优化: - ①char固定长度查询效率高,varchar第一个字节记录数据长度 - ②应该针对Explain中Rows增加索引 - ③group/order by字段均会涉及索引 - ④Limit中分页查询会随着start值增大而变缓慢,通过子查询+表连接解决
select * from mytbl order by id limit 100000,10;
-- 改进后的SQL语句如下
select * from mytbl where id >= ( select id from mytbl order by id limit 100000,1 ) limit 10
select * from mytbl inner join (select id from mytbl order by id limit 100000,10) as tmp on tmp.id=mytbl.id;
- ⑤count会进行全表扫描,如果估算可以使用explain - ⑥delete删除表时会增加大量undo和redo日志,确定删除可使用trancate
表结构优化: - ①单库不超过200张表 - ②单表不超过500w数据 - ③单表不超过40列 - ④单表索引不超过5个
配置优化: - 配置连接数、禁用Swap、增加内存、升级SSD硬盘
分库分表
分表用户id进行分表,每个表控制在300万数据。 分库根据业务场景和地域分库,每个库并发不超过2000 不是写瓶颈优先进行分表
Sharding-jdbc或Mycat
富查询:采用分库分表之后,如何满足跨越分库的查询?使用ES的宽表 数据倾斜:数据分库基础上再进行分表 深分页问题:按游标查询,或者叫每次查询都带上上一次查询经过排序后的最大 ID
双写不中断迁移:
- 线上系统里所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改
- 系统部署以后,还需要跑程序读老库数据写新库,写的时候需要判断updateTime
- 循环执行,直至两个库的数据完全一致,最后重新部署分库分表的代码就行了
深分页问题
- 内存排序
将
order by time offset X limit Y,改写成order by time offset 0 limit X+Y,服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录 - 禁止跳页查询
order by time where time > $time_max limit Y - 允许模糊数据
order by time offset X/N limit Y/N - 二次查询法
四、Redis篇
速度快,完全基于内存,使用C语言实现,网络层使用epoll解决高并发问题,单线程模型避免了不必要的上下文切换及竞争条件
redis数据类型
| 类型 | 底层 | 应用场景 | 编码类型 |
|---|---|---|---|
| String | SDS数组 | 帖子、评论、热点数据、输入缓冲 | RAW « EMBSTR « INT |
| List | QuickList | 评论列表、商品列表、发布与订阅、慢查询、监视器 | LINKEDLIST « ZIPLIST |
| Set | IntSet | 适合交集、并集、查集操作,例如朋友关系 | HT « INSET |
| Zset | 跳跃表 | 去重后排序,适合排名场景 | SKIPLIST « ZIPLIST |
| Hash | 哈希 | 结构化数据,比如存储对象 | HT « ZIPLIST |
| Stream | 紧凑列表 | 消息队列 |
SDS,用于存储字符串和整型数据及输入缓冲
struct sdshdr{
int len; // 记录buf数组中已使用字节的数量
int free; // 记录 buf 数组中未使用字节的数量
char buf[]; // 字符数组,用于保存字符串
}
跳跃表 Redis使用跳表而不使用红黑树,是因为跳表的索引结构序列化和反序列化更加快速,方便持久化。
字典dict Redis整个数据库是用字典来存储的(K-V结构) —Hash+数组+链表
渐进式rehash:根据服务器空闲程度批量rehash部分节点
五、Kafka篇
消息队列的作用:异步、削峰填谷、解耦 由于是异步的和批处理的,延迟也会高,不适合电商场景
六、Spring
AOP 动态代理
如果要代理的对象,实现了某个接⼝,那么Spring AOP会使⽤JDKProxy,去创建代理对象,⽽对于没有实现接⼝的对象,这时候Spring AOP会使⽤ Cglib ⽣成⼀个被代理对象的⼦类来作为代理
NoSQL
ElasticSearch 简介
概述
Elasticsearch是一个建立在全文搜索引擎库Apache Lucene 基础上的实时的分布式搜索和分析引擎,它可以帮助我们用很快的速度去处理大规模数据,可以用于全文检索、结构化检索、推荐、分析以及统计聚合等多种场景。
数据模型
Lucene
Lucene提供了最基本的索引和查询的功能,是一个单机的搜索库,并且没有主键概念和更新逻辑
Lucene/Elasticsearch数据模型
@startmindmap
*[#orange] 基本数据类型
**[#lightgreen]: Index 索引
由很多的Document组成;
**[#lightgreen]: Document 文档
由很多的Field组成,是Index和Search的最小单位;
**[#lightgreen]: Field 字段
由很多的Term组成,包括Field Name和Field Value;
**[#lightgreen]: Term 词元
由很多的字节组成,可以分词;
*[#orange] 索引类型
**[#lightblue]: Invert Index 倒排索引
索引的Key是Term,Value是DocID的链表
通过Term可以查询到拥有该Term的文档;
***[#cyan] 存储类型
****[#FFBBCC] DOCS 只存储DocID
****[#FFBBCC]: DOCS_AND_FREQS
存储DocID和词频TermFreq;
****[#FFBBCC]: DOCS_AND_FREQS_AND_POSITIONS
存储DocID、词频TermFreq和位置;
****[#FFBBCC]: DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS
存储DocID、词频TermFreq、位置和偏移;
**[#lightblue]: DocValues 正排索引
Key 是DocID和FieldName,Value是FieldValue
列式存储,通过DocID可以快速读取到该Doc的特定字段的值
一般用于sort,agg等需要高频读取Doc字段值的场景;
**[#lightblue]: Store 字段原始内容存储
Key是Doc ID,Value是FiledName和FiledValue
同一文档的多个Field的Store会存储在一起;
@endmindmap
Elasticsearch对Lucene的扩展
Elasticsearch通过增加_id、_version、_source、_routing和_seq_no等多个系统字段,实现了分布式搜索和部分字段更新等Lucene缺失的功能
| System Field | 含义 | Lucene Index | Lucene DocValues | Lucene Store |
|---|---|---|---|---|
| _uid | 主键 | Y | Y | |
| _version | 版本 | Y | ||
| _source | 原始值 | Y | ||
| _seq_no | 序号 | Y | Y | |
| _primary_term | 主编号 | Y | ||
| _routing | 路由 | Y | Y | |
| _field_names | 字段名 | Y |
1 _id
_id是一个用户级别的虚拟字段,Lucene不会存储该字段的值。表示Doc的主键,在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
Lucene中没有主键索引,要保证系统中同一个Doc不会重复,Elasticsearch引入了_id字段来实现主键。每次写入的时候都会先查询id,如果有,则说明已经有相同Doc存在了。
2 _uid
Index#Doc, Store
_uid的格式是:type + ‘#’ + id。同Index下值是唯一的
3 _version
DcoValues
每个Doc都会有一个Version,该Version可以由用户指定,也可以由系统自动生成。如果是系统自动生成,那么每次Version都是递增1。
Elasticsearch通过使用version来保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失:
- 首次写入Doc的时候,会为Doc分配一个初始的Version:V0,该值根据VersionType不同而不同。
- 再次写入Doc的时候,如果Request中没有指定Version,则会先加锁,然后去读取该Doc的最大版本V1,然后将V1+1后的新版本写入Lucene中。
- 再次写入Doc的时候,如果Request中指定了Version:V1,则继续会先加锁,然后去读该Doc的最大版本V2,判断V1==V2,如果不相等,则发生版本冲突。否则版本吻合,继续写入Lucene。
- 当做部分更新的时候,会先通过GetRequest读取当前id的完整Doc和V1,接着和当前Request中的Doc合并为一个完整Doc。然后执行一些逻辑后,加锁,再次读取该Doc的最大版本号V2,判断V1==V2,如果不相等,则在刚才执行其他逻辑时被其他线程更改了当前文档,需要报错后重试。如果相等,则期间没有其他线程修改当前文档,继续写入Lucene中。这个过程就是一个典型的read-then-update事务。
4 _source
Store
存储原始文档,也可以通过过滤设置只存储特定Field
_source字段的主要目的是通过doc_id读取该文档的原始内容,所以只需要存储Store即可
Elasticsearch中使用_source字段可以实现以下功能:
- Update:部分更新时,需要从读取文档保存在_source字段中的原文,然后和请求中的部分字段合并为一个完整文档。如果没有_source,则不能完成部分字段的Update操作。
- Rebuild:最新的版本中新增了rebuild接口,可以通过Rebuild API完成索引重建,过程中不需要从其他系统导入全量数据,而是从当前文档的_source中读取。如果没有_source,则不能使用Rebuild API。
- Script:不管是Index还是Search的Script,都可能用到存储在Store中的原始内容,如果禁用了_source,则这部分功能不再可用。 Summary:摘要信息也是来源于_source字段。
5 _seq_no
Index#DOCS_AND_FREQS_AND_POSITIONS, Analyzer, DocValues
严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no。
每个文档在使用Lucene的document操作接口之前,会获取到一个_seq_no,这个_seq_no会以系统保留Field的名义存储到Lucene中,文档写入Lucene成功后,会标记该seq_no为完成状态,这时候会使用当前seq_no更新local_checkpoint。
checkpoint分为local_checkpoint和global_checkpoint,主要是用于保证有序性,以及减少Shard恢复时数据拷贝的数据拷贝量。
Elasticsearch中_seq_no的作用有两个,一是通过doc_id查询到该文档的seq_no,二是通过seq_no范围查找相关文档,所以也就需要存储为Index和DocValues(或者Store)。由于是在冲突检测时才需要读取文档的_seq_no,而且此时只需要读取_seq_no,不需要其他字段,这时候存储为列式存储的DocValues比Store在性能上更好一些。
6 _primary_term
DocValues
每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。_primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。
Elasticsearch中_primary_term只需要通过doc_id读取到即可,所以只需要保存为DocValues就可以了.
7 _routing
Index#Doc, Store
在mapping中,或者Request中可以指定按某个字段路由。默认是按照_Id值路由。
Elasticsearch中文档级别的_routing主要有两个目的,一是可以查询到使用某种_routing的文档有哪些,当发生_routing变化时,可以对历史_routing的文档重新读取再Index,这个需要倒排Index。另一个是查询到文档后,在Response里面展示该文档使用的_routing规则,这里需要存储为Store。
8 _field_names
Index#Doc
该字段会索引某个Field的名称,用来判断某个Doc中是否存在某个Field,用于exists或者missing请求。
Elasticsearch中_field_names的目的是查询哪些Doc的这个Field是否存在,所以只需要倒排Index即可。
ElasticSearch 查询
查询流程
Lucene的读
TopDocs search(Query query, int n)返回最满足Query的N个结果Document doc(int docID)通过doc id查询Doc内容int count(Query query)通过Query获取到命中数
Search类实时(Near Real Time)请求:同时查询内存和磁盘上的Segment,最后将结果合并后返回。所有的搜索系统一般都是两阶段查询,第一阶段查询到匹配的DocID,第二阶段再查询DocID对应的完整文档,在Elasticsearch中称为query_then_fetch。而一阶段查询query_and_fetch,适用于查询一个Shard的请求。根据TF(Term Frequency)和DF(Document Frequency)来算分的查询使用三阶段查询,即先收集所有Shard中的TF和DF值,然后将这些值带入请求中,再次执行query_then_fetch,这样算分的时候TF和DF就是准确的,称作DFS_query_then_fetch,另有DFS_query_and_fetch。另一种选择是用BM25代替TF/DF模型
Get类实时(Real Time)请求:先查询内存中的TransLog,没找到则再查询磁盘上的TransLog,还没有则再查询磁盘上的Segment。这种查询顺序可以保证查询到最新版本的Doc
Client Node
Get Remove Cluster Shard 判断是否需要跨集群访问,如果需要,则获取到要访问的Shard列表
Get Search Shard Iterator 获取当前Cluster中要访问的Shard,和上一步中的Remove Cluster Shard合并,构建出最终要访问的完整Shard列表。 这一步中,会在Primary Node和多个Replica Node中选择出一个要访问的Shard
For Every Shard:Perform 遍历每个Shard,对每个Shard执行后面逻辑
Send Request To Query Shard 将查询阶段请求发送给相应的Shard
Merge Docs 上一步将请求发送给多个Shard后,这一步就是异步等待返回结果,然后对结果合并。这里的合并策略是维护一个Top N大小的优先级队列,每当收到一个shard的返回,就把结果放入优先级队列做一次排序,直到所有的Shard都返回。
Send Request To Fetch Shard 选出Top N个Doc ID后发送Fetch Shard给这些Doc ID所在的Shard,最后会返回Top N的Doc的内容。
Query Phase
Create Search Context 创建Search Context,之后Search过程中的所有中间状态都会存在Context中
Parse Query 解析Query的Source,将结果存入Search Context
Get From Cache 判断请求是否允许被Cache,如果允许,则检查Cache中是否已经有结果,如果有则直接读取Cache,如果没有则继续执行后续步骤,执行完后,再将结果加入Cache
Add Collectors Collector主要目标是收集查询结果,实现排序,自定义结果集过滤和收集等。这一步会增加多个Collectors,多个Collector组成一个List
Lucene::search 调用Lucene中IndexSearch的search接口,执行真正的搜索逻辑。每个Shard中会有多个Segment,每个Segment对应一个LeafReaderContext,这里会遍历每个Segment,到每个Segment中去Search结果,然后计算分数
Rescore 根据Request中是否包含rescore配置决定是否进行二阶段排序
Suggest::execute 如果有推荐请求,则在这里执行推荐请求。
Aggregation::execute 如果含有聚合统计请求,则在这里执行。Elasticsearch中的aggregate的处理逻辑也类似于Search,通过多个Collector来实现。在Client Node中也需要对aggregation做合并
Fetch Phase
通过DocID获取到用户需要的完整Doc内容。这些内容包括了DocValues,Store,Source,Script和Highlight等
ElasticSearch 写入
写入流程
写操作在搜索系统和NoSQL数据库中的对比
- 实时性:
- 搜索系统的Index一般都是NRT(Near Real Time),近实时的,比如Elasticsearch中,Index的实时性是由refresh控制的,默认是1s,最快可到100ms,那么也就意味着Index doc成功后,需要等待一秒钟后才可以被搜索到。
- NoSQL数据库的Write基本都是RT(Real Time),实时的,写入成功后,立即是可见的。Elasticsearch中的Index请求也能保证是实时的,因为Get请求会直接读内存中尚未Flush到存储介质的TransLog。
- 可靠性:
- 搜索系统对可靠性要求都不高,一般数据的可靠性通过将原始数据存储在另一个存储系统来保证,当搜索系统的数据发生丢失时,再从其他存储系统导一份数据过来重新rebuild就可以了。在Elasticsearch中,通过设置TransLog的Flush频率可以控制可靠性,要么是按请求,每次请求都Flush;要么是按时间,每隔一段时间Flush一次。一般为了性能考虑,会设置为每隔5秒或者1分钟Flush一次,Flush间隔时间越长,可靠性就会越低。
- NoSQL数据库作为一款数据库,必须要有很高的可靠性,数据可靠性是生命底线,决不能有闪失。如果把Elasticsearch当做NoSQL数据库,此时需要设置TransLog的Flush策略为每个请求都要Flush,这样才能保证当前Shard写入成功后,数据能尽量持久化下来。
写操作的关键点
- 可靠性:或者是持久性,数据写入系统成功后,数据不会被回滚或丢失。
- 一致性:数据写入成功后,再次查询时必须能保证读取到最新版本的数据,不能读取到旧数据。
- 原子性:一个写入或者更新操作,要么完全成功,要么完全失败,不允许出现中间状态。
- 隔离性:多个写入操作相互不影响。
- 实时性:写入后是否可以立即被查询到。
- 性能:写入性能,吞吐量到底怎么样。
Elasticsearch的写
Replica 副本
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。
Elasticsearch整体架构上采用了一主多副的方式:
@startuml
!theme mars
skinparam component {
BackgroundColor gold
ArrowColor #FF6655
}
frame "DataNode" as primary {
node [Primary] as p1
}
frame "DataNode" as replica1 {
node [Replica1] as r1
p1 --> r1
}
frame "DataNode" as replica2 {
node [Replica2] as r2
p1 --> r2
}
@enduml
每个Index由多个Shard组成,每个Shard有一个主节点和多个副本节点,副本个数可配。但每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard(在OperationRouting类中),最后从集群的Meta中找出出该Shard的Primary节点。
请求接着会发送给Primary Shard,在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端。
这种模式下,写入操作的延时就等于latency = Latency(Primary Write) + Max(Replicas Write)。只要有副本在,写入延时最小也是两次单Shard的写入时延总和,写入效率会较低,但是这样的好处也很明显,避免写入后,单机或磁盘故障导致数据丢失,在数据重要性和性能方面,一般都是优先选择数据,除非一些允许丢数据的特殊场景。
Elasticsearch里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如5分钟)才会把Lucene的Segment写入磁盘持久化,对于写入内存,但还未Flush到磁盘的Lucene数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候Elasticsearch使用TransLog来保证数据不丢失
TransLog
对于每一个Shard,写入请求到达该Shard后,先写Lucene文件,创建好索引,此时索引还在内存里面,接着去写TransLog,写完TransLog后,刷新TransLog数据到磁盘上,写磁盘成功后,请求返回给用户。
在写Lucene内存后,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到,所以Elasticsearch在搜索方面是NRT(Near Real Time)近实时的系统。而如果写完之后实时使用GetById查询,则可以直接从TransLog中查询到,这时候就成了RT(Real Time)实时系统。
每隔一段比较长的时间,比如30分钟后,Lucene会把内存中生成的新Segment刷新到磁盘上,这时会清空掉旧的TransLog。
Update流程
@startuml
!theme mars
start
:Update请求;
:GetDocById,找到相应的文档Doc;
if (内存TransLog上找到该文档) then (yes)
elseif (磁盘TransLog上找到该文档) then (yes)
elseif (磁盘Lucene Segment上找到该文档) then (yes)
else (nothing)
:文档未找到;
stop
endif
:找到完整Doc后,记录版本号为V1;
:将版本V1的全量Doc和请求中的部分字段Doc合并为一个完整的Doc
后续操作相当于Index请求+Delete请求,即先增后删;
:加锁;
:从versionMap中读取该id的最大版本号V2;
if (检查版本是否冲突V1==V2) then (冲突)
:回退到开始的“Update doc”阶段,重新执行;
endif
:将Version + 1得到V3,再将Doc加入到Lucene中去;
:写入Lucene成功后,将当前V3更新到versionMap中;
:释放锁;
end
@enduml
Client Node
Ingest Pipeline 在这一步可以对原始文档做一些处理,比如HTML解析,自定义的处理,具体处理逻辑可以通过插件来实现。在Elasticsearch中,由于Ingest Pipeline会比较耗费CPU等资源,可以设置专门的Ingest Node,专门用来处理Ingest Pipeline逻辑。如果当前Node不能执行Ingest Pipeline,则会将请求发给另一台可以执行Ingest Pipeline的Node
Auto Create Index 判断当前Index是否存在,如果不存在,则需要自动创建Index,这里需要和Master交互。也可以通过配置关闭自动创建Index的功能
Set Routing 设置路由条件,如果Request中指定了路由条件,则直接使用Request中的Routing,否则使用Mapping中配置的,如果Mapping中无配置,则使用默认的_id字段值。在这一步中,如果没有指定id字段,则会自动生成一个唯一的_id字段,目前使用的是UUID
Construct BulkShardRequest 由于Bulk Request中会包括多个(Index/Update/Delete)请求,这些请求根据routing可能会落在多个Shard上执行,这一步会按Shard挑拣Single Write Request,同一个Shard中的请求聚集在一起,构建BulkShardRequest,每个BulkShardRequest对应一个Shard
Send Request To Primary 这一步会将每一个BulkShardRequest请求发送给相应Shard的Primary Node
Primary Node
PrimaryOperationTransportHandler.messageReceived
1. Index or Update or Delete
循环执行每个Single Write Request,对于每个Request,根据操作类型(CREATE/INDEX/UPDATE/DELETE)选择不同的处理逻辑。其中,Create/Index是直接新增Doc,Delete是直接根据_id删除Doc
2. Translate Update To Index or Delete
这一步是Update操作的特有步骤,在这里,会将Update请求转换为Index或者Delete请求。首先,会通过GetRequest查询到已经存在的同_id Doc(如果有)的完整字段和值(依赖_source字段),然后和请求中的Doc合并。同时,这里会获取到读到的Doc版本号,记做V1
3. Parse Doc
这里会解析Doc中各个字段。生成ParsedDocument对象,同时会生成uid Term
4. Update Mapping
Elasticsearch中有个自动更新Mapping的功能,就在这一步生效。会先挑选出Mapping中未包含的新Field,然后判断是否运行自动更新Mapping,如果允许,则更新Mapping
5. Get Sequence Id and Version
由于当前是Primary Shard,则会从SequenceNumber Service获取一个sequenceID和Version。SequenceID在Shard级别每次递增1,SequenceID在写入Doc成功后,会用来初始化LocalCheckpoint。Version则是根据当前Doc的最大Version递增1
6. Add Doc To Lucene
这一步开始的时候会给特定_uid加锁,然后判断该_uid对应的Version是否等于之前Translate Update To Index步骤里获取到的Version,如果不相等,则说明刚才读取Doc后,该Doc发生了变化,出现了版本冲突,这时候会抛出一个VersionConflict的异常,该异常会在Primary Node最开始处捕获,重新从“Translate Update To Index or Delete”开始执行
如果Version相等,则继续执行,如果已经存在同id的Doc,则会调用Lucene的UpdateDocument(uid, doc)接口,先根据uid删除Doc,然后再Index新Doc。如果是首次写入,则直接调用Lucene的AddDocument接口完成Doc的Index,AddDocument也是通过UpdateDocument实现
这里如何保证Delete-Then-Add的原子性,怎么避免中间状态时被Refresh?答案是在开始Delete之前,会加一个Refresh Lock,禁止被Refresh,只有等Add完后释放了Refresh Lock后才能被Refresh,这样就保证了Delete-Then-Add的原子性
7. Write Translog
写完Lucene的Segment后,会以keyvalue的形式写TransLog,Key是_id,Value是Doc内容。当查询的时候,如果请求是GetDocByID,则可以直接根据_id从TransLog中读取到,满足NoSQL场景下的实时性要去。这一步的最后,会标记当前SequenceID已经成功执行,接着会更新当前Shard的LocalCheckPoint
8. Renew Bulk Request
这里会重新构造Bulk Request
9. Flush Translog
这里会根据TransLog的策略,选择不同的执行方式,要么是立即Flush到磁盘,要么是等到以后再Flush。Flush的频率越高,可靠性越高,对写入性能影响越大
10. Send Requests To Replicas
这里会将刚才构造的新的Bulk Request并行发送给多个Replica,然后等待Replica的返回,这里需要等待所有Replica返回后(可能有成功,也有可能失败),Primary Node才会返回用户。如果某个Replica失败了,则Primary会给Master发送一个Remove Shard请求,要求Master将该Replica Shard从可用节点中移除。同时会将SequenceID,PrimaryTerm,GlobalCheckPoint等传递给Replica
发送给Replica的请求中,Action Name等于原始ActionName + [R],这里的R表示Replica。通过这个[R]的不同,可以找到处理Replica请求的Handler
11. Receive Response From Replicas
Replica中请求都处理完后,会更新Primary Node的LocalCheckPoint
Replica Node
ReplicaOperationTransportHandler.messageReceived
1. Index or Delete
2. Parse Doc
3. Update Mapping
4. Get Sequence Id and Version
Primary Node中会生成Sequence ID和Version,然后放入ReplicaRequest中,这里只需要从Request中获取到就行
5. Add Doc To Lucene
6. Write Translog
7. Flush Translog
写操作的关键点
- 可靠性:由于Lucene的设计中不考虑可靠性,在Elasticsearch中通过Replica和TransLog两套机制保证数据的可靠性。
- 一致性:Lucene中的Flush锁只保证Update接口里面Delete和Add中间不会Flush,但是Add完成后仍然有可能立即发生Flush,导致Segment可读。这样就没法保证Primary和所有其他Replica可以同一时间Flush,就会出现查询不稳定的情况,这里只能实现最终一致性。
- 原子性:Add和Delete都是直接调用Lucene的接口,是原子的。当部分更新时,使用Version和锁保证更新是原子的。
- 隔离性:仍然采用Version和局部锁来保证更新的是特定版本的数据。
- 实时性:使用定期Refresh Segment到内存,并且Reopen Segment方式保证搜索可以在较短时间(比如1秒)内被搜索到。通过将未刷新到磁盘数据记入TransLog,保证对未提交数据可以通过ID实时访问到。
- 性能:一是不需要所有Replica都返回后才能返回给用户,只需要返回特定数目的就行;二是生成的Segment先在内存中提供服务,等一段时间后才刷新到磁盘,Segment在内存这段时间的可靠性由TransLog保证;三是TransLog可以配置为周期性的Flush,但这个会给可靠性带来伤害;四是每个线程持有一个Segment,多线程时相互不影响,相互独立,性能更好;五是系统的写入流程对版本依赖较重,读取频率较高,因此采用了versionMap,减少热点数据的多次磁盘IO开销。
Elasticsearch 查询性能
Lucene查询原理
Lucene的数据结构
FST
保存term字典,可以在FST上实现单Term、Term范围、Term前缀和通配符查询等
对字符串范围/前缀/通配符查询,Lucene会从FST中获取到符合条件的所有Term,然后就可以根据这些Term再查找倒排链,找到符合条件的doc。FST相关的字符串查询要比倒排链查询慢很多(以上10倍)
倒排链
保存了每个term对应的docId的列表,采用skipList的结构保存,用于快速跳跃
对单个词条进行查询,Lucene会读取该词条的倒排链,倒排链中是一个有序的docId列表。单个倒排链扫描的性能在每秒千万级
BKD-Tree
BKD-Tree是一种保存多维空间点的数据结构,用于数值类型(包括空间点)的快速查找
对数字类型进行范围查找,Lucene会通过BKD-Tree找到符合条件的docId集合,但这个集合中的docId并非有序的。和其他条件做交集的时候,需要构建有序的docID数组或BitSet
DocValues
基于docId的列式存储,由于列式存储的特点,可以有效提升排序聚合的性能
IndexSorting
IndexSorting是一种预排序,即数据预先按照某种方式进行排序,它是Index的一个设置,这里数据是在每个Segment内有序。一个Segment中的每个文档,都会被分配一个docID,docID从0开始,顺序分配。在没有IndexSorting时,docID是按照文档写入的顺序进行分配的,在设置了IndexSorting之后,docID的顺序就与IndexSorting的顺序一致
优化查询性能
提前中断
查询的Sort顺序与IndexSorting的顺序相同,并且不需要获取符合条件的记录总数(TotalHits)时,这时候可以提前中断查询
提高数据压缩率
不管行存(Store)与列存(DocValues)的存储方式,应用IndexSorting后,相邻数据的相似度就会越高,也就越利于压缩
降低写入性能
实现原理
Flush时保证Segment内数据有序
数据写入Lucene后,并不是立即可查的,要生成Segment之后才能被查到。为了保证近实时的查询,ES会每隔一秒进行一次Refresh,Refresh就会调用到Lucene的Flush生成新的Segment
每个doc写入进来之后,按照写入顺序被分配一个docID,然后被IndexingChain处理,依次要对invert index、store fields、doc values和point values进行处理,有些数据会直接写到文件里,主要是store field和term vector,其他的数据会放到memory buffer中
在Flush时,首先根据设定的列排序,这个排序可以利用内存中的doc values,排序之后得到老的docID到新docID的映射,因为之前docID是按照写入顺序生成的,现在重排后,生成的是新的排列。对于已经写到文件中的数据,比如store field和term vector,需要从文件中读出来,重新排列后再写到一个新文件里,原来的文件就相当于一个临时文件。对于内存中的数据结构,直接在内存中重排后写到文件中。
相比没有IndexSorting时,对性能影响比较大的一块就是store field的重排,因为这部分需要从文件中读出再写回,而其他部分都是内存操作,性能影响稍小一些
Merge时保证新的Segment数据有序
由于Flush时Segment已经是有序的了,所以在Merge时也就可以采用非常高效的Merge Sort的方式进行
Elasticsearch 分布式原理Node篇
ES集群构成
配置文件 conf/elasticsearch.yml
node.master: true
node.data: false
当node.master为true时,其表示这个node是一个master的候选节点,可以参与选举,在ES的文档中常被称作 master-eligible node,类似于Leader和Candidate的关系。当node.data为true时,这个节点作为一个数据节点,会存储分配在该node上的shard的数据并负责这些shard的写入、查询等。此外,任何一个集群内的node都可以执行任何请求,其会负责将请求转发给对应的node进行处理
节点发现
ES ZenDiscovery在选举时没有term的概念,不能保证每轮每个节点只投一票
Node启动后,首先要通过节点发现功能加入集群。ZenDiscovery是ES自己实现的一套用于节点发现和选主等功能的模块
# 推荐这里设置为所有的master-eligible node
discovery.zen.ping.unicast.hosts: [x.x.x.1, x.x.x.2, x.x.x.3]
Master选举
保证选举出的master被多数派(quorum)的master-eligible node认可,以此来保证只有一个master
# 设置 quorum
discovery.zen.minimum_master_nodes: 2
master选举发起的时机
当一个节点发现包括自己在内的多数派的master-eligible节点认为集群没有master时,就可以发起master选举
- 该master-eligible节点的状态为
当前没有master - 该master-eligible节点通过ZenDiscovery模块的ping操作询问其已知的集群其他节点的信息,获取到的状态都为
当前没有master - 包括本节点在内,当前已有超过minimum_master_nodes个节点认为集群没有master
master选举的投票对象
当clusterStateVersion越大,优先级越高。这是为了保证新Master拥有最新的clusterState(即集群的meta),避免已经commit的meta变更丢失
class Some {
// 计算出选举的投票对象
public MasterCandidate electMaster(Collection<MasterCandidate> candidates) {
assert hasEnoughCandidates(candidates);
List<MasterCandidate> sortedCandidates = new ArrayList<>(candidates);
sortedCandidates.sort(MasterCandidate::compare);
return sortedCandidates.get(0);
}
// 先根据节点的clusterStateVersion比较,相同时,则按照节点的Id比较(Id为节点第一次启动时随机生成)
public static int compare(MasterCandidate c1, MasterCandidate c2) {
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}
}
达成选举
假设Node_A选Node_B当Master
Node_A会向Node_B发送join请求,那么此时:
(1) 如果Node_B已经成为Master,那么Node_B就会把Node_A加入到集群中,然后发布最新的cluster_state, 最新的cluster_state就会包含Node_A的信息。相当于一次正常情况的新节点加入。对于Node_A,等新的cluster_state发布到Node_A的时候,Node_A也就完成join了
(2) 如果Node_B在竞选Master,那么Node_B会把这次join当作一张选票。对于这种情况,Node_A会等待一段时间,看Node_B是否能成为真正的Master,直到超时或者有别的Master选成功。、
(3) 如果Node_B认为自己不是Master(现在不是,将来也选不上),那么Node_B会拒绝这次join。对于这种情况,Node_A会开启下一轮选举
假设Node_A选自己当Master
此时NodeA会等别的node来join,即等待别的node的选票,当收集到超过半数的选票时,认为自己成为master,然后变更cluster_state中的master node为自己,并向集群发布这一消息
脑裂保证
一个节点可能在相邻的两轮选主中选择不同的主,恰好导致这两个被选的节点都成为了主。但是这种脑裂很快会自动恢复,因为不一致发生后某个master再次发布cluster_state时就会发现无法达到多数派条件,或者是发现它的follower并不构成多数派而自动降级为candidate等
错误检测
MasterFaultDetection Master定期检测集群内其他的Node
如果Master检测到某个Node连不上了,会执行removeNode的操作,将节点从cluster_state中移除,并发布新的cluster_state。当各个模块apply新的cluster_state时,就会执行一些恢复操作,比如选择新的primaryShard或者replica,执行数据复制等
NodesFaultDetection 集群内其他的Node定期检测当前集群的Master
如果某个Node发现Master连不上了,会清空pending在内存中还未commit的new cluster_state,然后发起rejoin,重新加入集群(如果达到选举条件则触发新master选举)。
rejoin
Master发现自己已经不满足多数派条件(>=minimumMasterNodes)了,需要主动退出master状态(退出master状态并执行rejoin)以避免脑裂的发生
electMasterService.hasEnoughMasterNodes当有节点连不上时,会执行removeNode。在执行removeNode时判断剩余的Node是否满足多数派条件,如果不满足,则执行rejoinpublishClusterState.publish在publish新的cluster_state时,分为send阶段和commit阶段,send阶段要求多数派必须成功,然后再进行commit。如果在send阶段没有实现多数派返回成功,那么可能是有了新的master或者是无法连接到多数派个节点等,则master需要执行rejoinotherClusterStateVersion > localClusterState.version()在对其他节点进行定期的ping时,发现有其他节点也是master,此时会比较本节点与另一个master节点的cluster_state的version,谁的version大谁成为master,version小的执行rejoin
集群扩缩容
扩容DataNode
rebalance
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html
缩容DataNode
https://www.elastic.co/guide/en/elasticsearch/reference/current/allocation-filtering.html
PUT /_cluster/settings
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
扩容MasterNode
先增大quorum,然后扩容节点
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 3
}
}'
缩容MasterNode
缩容MasterNode与扩容跟扩容是相反的流程,我们需要先把节点缩下来,再把quorum数调下来
Elasticsearch 分布式原理Meta篇
Meta数据
Master节点管理Meta数据并通知其他节点,来驱动各个模块工作,比如创建Shard等
Meta是用来描述数据的数据。在ES中,Index的mapping结构、配置、持久化状态等就属于meta数据,集群的一些配置信息也属于meta。这类meta数据非常重要,假如记录某个index的meta数据丢失了,那么集群就认为这个index不再存在了。ES中的meta数据只能由master进行更新
Meta数据结构
集群中的每个节点都会在内存中维护一个当前的ClusterState,表示当前集群的各种状态
ClusterState
class ClusterState {
long version; // 当前版本号,每次更新加1
String stateUUID; // 该state对应的唯一id
RoutingTable routingTable; // 所有index的路由表
DiscoveryNodes nodes; // 当前集群节点
MetaData metaData; // 集群的meta数据,需要持久化
ClusterBlocks blocks; // 用于屏蔽某些操作
ImmutableOpenMap<String, Custom> customs; // 自定义配置
ClusterName clusterName; // 集群名
}
MetaData
class MetaData {
String clusterUUID; // 集群的唯一id
long version; // 当前版本号,每次更新加1
Settings persistentSettings; // 持久化的集群设置
ImmutableOpenMap<String, IndexMetaData> indices; // 所有Index的Meta
ImmutableOpenMap<String, IndexTemplateMetaData> templates; // 所有模版的Meta
ImmutableOpenMap<String, Custom> customs; // 自定义配置
}
IndexMetaData
class IndexMetaData {
long version; // 当前版本号,每次更新加1
int routingNumShards:; // 用于routing的shard数, 只能是该Index的numberOfShards的倍数,用于split
State state; // Index的状态, OPEN或CLOSE
Settings settings; // numbersOfShards,numbersOfRepilicas等配置
ImmutableOpenMap<String, MappingMetaData> mappings; // Index的mapping
ImmutableOpenMap<String, Custom> customs; // 自定义配置。
ImmutableOpenMap<String, AliasMetaData> aliases; // 别名
long[] primaryTerms; // primaryTerm在每次Shard切换Primary时加1,用于保序
ImmutableOpenIntMap<Set<String>> inSyncAllocationIds; // 处于InSync状态的AllocationId,用于保证数据一致性
}
Meta的存储
位于节点的data目录
nodes/$node_id/_state/
global-1.st 存储MetaData中除去IndexMetaData的部分
node-0.st 存储NodeId
nodes/$node_id/indices/$index_id/_state/
state-2.st 存储IndexMetaData
nodes/$node_id/indices/$index_id/$shard_id/_state/
state-0.st 存储ShardStateMetaData,包含是否是primary和allocationId等信息
Meta的恢复
当Master进程决定进行恢复Meta时,它会向集群中的MasterNode和DataNode请求其机器上的MetaData。对于集群的Meta,选择其中version最大的版本。对于每个Index的Meta,也选择其中最大的版本。然后将集群的Meta和每个Index的Meta再组合起来,构成当前的最新Meta
ClusterState commit的一致性
MasterService串行处理ClusterState的变更
有缺陷的两阶段提交
把Master发布ClusterState分成两步,第一步是向所有节点send最新的ClusterState,当有超过半数的master节点返回ack时,再发送commit请求,要求节点commit接收到的ClusterState。如果没有超过半数的节点返回ack,那么认为本次发布失败,同时退出master状态,执行rejoin重新加入集群
一致性问题:如果master在commit阶段,只commit了少数几个节点就出现了网络分区,将master与这几个少数节点分在了一起,其他节点可以互相访问。此时其他节点构成多数派,会选举出新的master,由于这部分节点中没有任何节点commit了新的ClusterState,所以新的master仍会使用更新前的ClusterState,造成Meta不一致
解决方案
实现一个标准的一致性算法,比如raft
raft算法中,follower接收到日志后就会进行持久化,写到磁盘上。ES中,节点接收到ClusterState只是放到内存中的一个队列中即返回,并不持久化
借助额外的组件保证meta一致性
用Zookeeper来保证Meta的一致性
使用共享存储来保存Meta
首先保证不会出现脑裂,然后可以使用共享存储来保存Meta
Elasticsearch 分布式原理Data篇
Replication写入流程
ES中每个Index会划分为多个Shard,Shard分布在不同的Node上,以此来实现分布式的存储和查询,支撑大规模的数据集。对于每个Shard,又会有多个Shard的副本,其中一个为Primary,其余的一个或多个为Replica。数据在写入时,会先写入Primary,由Primary将数据再同步给Replica。在读取时,为了提高读取能力,Primary和Replica都会接受读请求
1. 检查Active的Shard数
wait_for_active_shards 在每次写入前,该shard至少具有的active副本数
2. 写入Primary
3. 并发的向所有Replicate发起写入请求
4. 等所有Replicate返回或者失败后,返回给Client
如果Replica写入失败,ES会执行一些重试逻辑等,但最终并不强求一定要在多少个节点写入成功
如果一个Replica写失败了,Primary会将这个信息报告给Master,然后Master会在Meta中更新这个Index的InSyncAllocations配置,将这个Replica从中移除,移除后它就不再承担读请求
PacificA算法
一种用于日志复制系统的分布式一致性算法
- 强一致性
- 单Primary向多Secondary的数据同步模式
- 使用额外的一致性组件Configuration Manager维护Configuration
- 少数派Replica可用时仍可写入
名词解释
Replica Group
一个互为副本的数据集合叫做Replica Group,每个副本是一个Replica。一个Replica Group中只有一个副本是Primary,其余为Secondary
Configuration
一个Replica Group的Configuration描述了这个Replica Group包含哪些副本,其中Primary是谁等
Configuration Version
Configuration的版本号,每次Configuration发生变更时加1
Configuration Manager
管理Configuration的全局组件,其保证Configuration数据的一致性。Configuration变更会由某个Replica发起,带着Version发送给Configuration Manager,Configuration Manager会检查Version是否正确,如果不正确则拒绝更改
Query & Update
对一个Replica Group的操作分为两种,Query和Update,Query不会改变数据,Update会更改数据
Serial Number sn
代表每个Update操作执行的顺序,每次Update操作加1,为连续的数字
Prepared List
Update操作的准备序列
Committed List
Update操作的提交序列,提交序列中的操作一定不会丢失(除非全部副本挂掉)。在同一个Replica上,Committed List一定是Prepared List的前缀
Primary Invariant
任何时候,当一个Replica认为自己是Primary时,Configuration Manager中维护的Configuration也认为其是当前的Primary。任何时候,最多只有一个Replica认为自己是这个Replica Group的Primary
如果不能满足Primary Invariant,那么Query请求就可能发送给Old Primary,读到旧的数据
Primary会定期获取一个Lease,获取之后认为某段时间内自己肯定是Primary,一旦超过这个时间还未获取到新的Lease就退出Primary状态。只要各个机器的CPU不出现较大的时钟漂移,那么就能够保证Lease机制的有效性
实现Lease机制的方式是,Primary定期向所有Secondary发送心跳来获取Lease,而不是所有节点都向某个中心化组件获取Lease。这样的好处是分散了压力,不会出现中心化组件故障而导致所有节点失去Lease的情况
Commited Invariant
SecondaryCommittedList一定是PrimaryCommittedList的前缀,PrimaryCommittedList一定是SecondaryPreparedList的前缀
Query
Query只能发送给Primary,Primary根据最新commit的数据,返回对应的值。由于算法要求满足Primary Invariant,所以Query总是能读到最新commit的数据
Update
- Primary分配一个Serial Number(简称sn)给一个UpdateRequest
- Primary将这个UpdateRequest加入自己的Prepared List,同时向所有Secondary发送Prepare请求,要求将这个UpdateRequest加入Prepared List
- 当所有Replica都完成了Prepare,即所有Replica的Prepared List中都包含了该Update请求时,Primary开始Commit这个请求,即将这个UpdateRequest放入Committed List中,同时Apply这个Update。因为同一个Replica上,Committed List永远是Prepared List的前缀,所以Primary实际上是提高Committed Point,把这个Update Request包含进来
- 返回客户端,Update操作成功
当下一次Primary向Secondary发送请求时,会带上Primary当前的Committed Point,此时Secondary才会提高自己的Committed Point
Reconfiguration Invariant
当一个新的Primary在T时刻完成Reconciliation时,那么T时刻之前任何节点(包括原Primary)的Commited List都是新Primary当前Commited List的前缀
Reconfiguration Invariant表明了已经Commit的数据在Reconfiguration过程中不会丢
1. Secondary故障
当一个Secondary故障时,Primary向Configuration Manager发起Reconfiguration,将故障节点从Replica Group中删除。一旦移除这个Replica,它就不属于这个Replica Group了,所有请求都不会再发给它
假设某个Primary和Secondary发生了网络分区,但是都可以连接Configuration Manager。这时候Primary会检测到Secondary没有响应了,Secondary也会检测到Primary没有响应。此时两者都会试图发起Reconfiguration,将对方从Replica Group中移除,这里的策略是First Win的原则,谁先到Configuration Manager中更改成功,谁就留在Replica Group里,而另外一个已经不属于Replica Group了,也就无法再更新Configuration了。由于Primary会向Secondary请求一个Lease,在Lease有效期内Secondary不会执行Reconfiguration,而Primary的探测间隔必然是小于Lease时间的
2. Primary故障
当一个Primary故障时,Secondary会收不到Primary的心跳,如果超过Lease的时间,那么Secondary就会发起Reconfiguration,将Primary剔除,这里也是First Win的原则,哪个Secondary先成功,就会变成Primary
当一个Secondary变成Primary后,需要先经过一个叫做Reconciliation的阶段才能提供服务。由于上述的Commited Invariant,所以原先的Primary的Committed List一定是新的Primary的Prepared List的前缀,那么我们将新的Primary的Prepared List中的内容与当前Replica Group中的其他节点对齐,相当于把该节点上未Commit的记录在所有节点上再Commit一次,那么就一定包含之前所有的Commit记录
3. 新加节点
新加的节点需要先成为Secondary Candidate,这时候Primary就开始向其发送Prepare请求,此时这个节点还会追之前未同步过来的记录,一旦追平,就申请成为一个Secondary,然后Primary向Configuration Manager发起配置变更,将这个节点加入Replica Group
如果一个节点曾经在Replica Group中,由于临时发生故障被移除,现在需要重新加回来。此时这个节点上的Commited List中的数据肯定是已经被Commit的了,但是Prepared List中的数据未必被Commit,所以应该将未Commit的数据移除,从Committed Point开始向Primary请求数据
SequenceNumber、Checkpoint与故障恢复
Term和SequenceNumber
每个写操作都会分配两个值,Term和SequenceNumber。Term在每次Primary变更时都会加1,类似于PacificA论文中的Configuration Version。SequenceNumber在每次操作后加1,类似于PacificA论文中的Serial Number。由于写请求总是发给Primary,所以Term和SequenceNumber会由Primary分配,在向Replica发送同步请求时,会带上这两个值
LocalCheckpoint和GlobalCheckpoint
LocalCheckpoint代表本Shard中所有小于该值的请求都已经处理完毕。GlobalCheckpoint代表所有小于该值的请求在所有的Replica上都处理完毕。GlobalCheckpoint会由Primary进行维护,每个Replica会向Primary汇报自己的LocalCheckpoint,Primary根据这些信息来提升GlobalCheckpoint
GlobalCheckpoint是一个全局的安全位置,代表其前面的请求都被所有Replica正确处理了,可以应用在节点故障恢复后的数据回补。另一方面,GlobalCheckpoint也可以用于Translog的GC,因为之前的操作记录可以不保存了
快速故障恢复
当一个Replica故障时,ES会将其移除,当故障超过一定时间,ES会分配一个新的Replica到新的Node上,此时需要全量同步数据。但是如果之前故障的Replica回来了,就可以只回补故障之后的数据,追平后加回来即可,实现快速故障恢复。实现快速故障恢复的条件有两个,一个是能够保存故障期间所有的操作以及其顺序,另一个是能够知道从哪个点开始同步数据。第一个条件可以通过保存一定时间的Translog实现,第二个条件可以通过Checkpoint实现,所以就能够实现快速的故障恢复
ES与PacificA的比较
- Meta一致性和Data一致性分开处理:PacificA中通过Configuration Manager维护Configuration的一致性,ES中通过Master维护Meta的一致性
- 维护同步中的副本集合:PacificA中维护Replica Group,ES中维护InSyncAllocationIds
- SequenceNumber:在PacificA和ES中,写操作都具有SequenceNumber,记录操作顺序
Lucene 简介
简介
Apache Lucene是一个开源的高性能、可扩展的信息检索引擎,提供了强大的数据检索能力
- Scalable, High-Performance Indexing
- Powerful, Accurate and Efficient Search Algorithms
概念
Index(索引)
类似数据库的表的概念,但是没有Scheme,相当于Document的集合
Document(文档)
类似数据库内的行或者文档数据库内的文档的概念,写入Index的Document会被分配一个唯一的ID,即Sequence Number(更多被叫做DocId)
Field(字段)
一个Document会由一个或多个Field组成,Field是Lucene中数据索引的最小定义单位。Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等
Term和Term Dictionary
Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。Term Dictionary即Term词典,是根据条件查找Term的基本索引
Segment
一个Index会由一个或多个sub-index构成,sub-index被称为Segment。Lucene的Segment设计思想,与LSM类似但又有些不同,继承了LSM中数据写入的优点,但是在查询上只能提供近实时而非实时查询
Lucene中的数据写入会先写内存的一个Buffer(类似LSM的MemTable,但是不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。删除时,由另外一个文件保存需要被删除的文档的DocID。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并,这点与LSM对SSTable的Merge类似
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的。原因是Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引
Sequence Number
DocId(即Sequence Number)实际上并不在Index内唯一,而是Segment内唯一,取值从0开始递增,且不一定连续,如果有Doc被删除,那可能会存在空洞。一个文档对应的DocId可能会发生变化,主要是发生在Segment合并时
Field(字段)
class Field {
protected final IndexableFieldType type;
protected final String name;
protected Object fieldsData;
}
interface IndexableFieldType {
boolean stored(); // 是否需要保存该字段
boolean tokenized(); // 是否做分词,针对TextField
boolean storeTermVectors(); // 是否储存Term Vector,对于长度较小的字段不建议开启
boolean omitNorms(); // 允许每个文档的每个字段都存储一个normalization factor
IndexOptions indexOptions();
DocValuesType docValuesType();
int pointDimensionCount(); // 多维数据的索引,一般经纬度数据会采取这个索引方式
int pointIndexDimensionCount();
int pointNumBytes();
int vectorDimension();
}
Term Vector
保存了一个文档内所有的term的相关信息,包括Term值、出现次数(frequencies)以及位置(positions)等,是一个per-document inverted index,提供了根据docid来查找该文档内所有term信息的能力。Term Vector的用途主要有两个,一是关键词高亮,二是做文档间的相似度匹配(more-like-this)
Normalization Factor
和搜索时的相关性计算有关的一个系数。Norms存储占一个字节,每个文档的每个字段都会独立存储一份,且Norms数据会全部加载到内存。若关闭了Norms,则无法做index-time boosting以及length normalization
IndexOptions
倒排索引的5种可选参数,用于选择该字段是否需要被索引,以及索引哪些内容
enum IndexOptions {
NONE,
DOCS,
DOCS_AND_FREQS,
DOCS_AND_FREQS_AND_POSITIONS,DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS
}
DocValue
正向索引(docid到field的一个列存)
enum DocValuesType {
NONE,
NUMERIC,
BINARY,
SORTED,
SORTED_NUMERIC,
SORTED_SET
}
数据结构
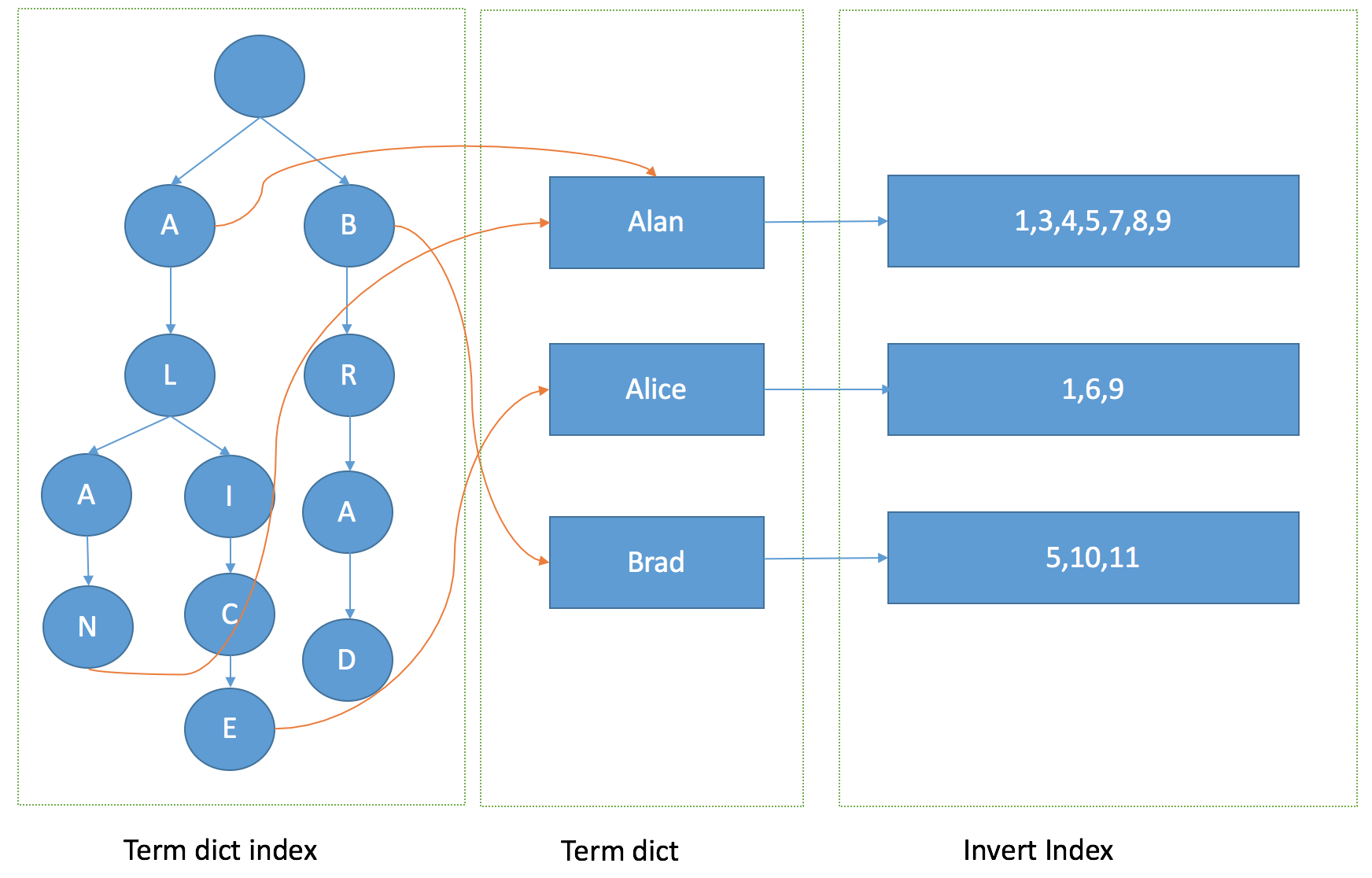
FST
Lucene使用FST数据结构来存储Term Dict Index
有向无环图,在范围,前缀搜索以及压缩率上都有明显的优势
BKDTree
Lucene IndexWriter
IndexWriterConfig
IndexDeletionPolicy:Lucene开放对commit point的管理,通过对commit point的管理可以实现例如snapshot等功能。Lucene默认配置的DeletionPolicy,只会保留最新的一个commit point
Similarity:搜索的核心是相关性,Similarity是相关性算法的抽象接口,Lucene默认实现了TF-IDF和BM25算法。相关性计算在数据写入和搜索时都会发生,数据写入时的相关性计算称为Index-time boosting,计算Normalizaiton并写入索引,搜索时的相关性计算称为query-time boosting
MergePolicy:Lucene内部数据写入会产生很多Segment,查询时会对多个Segment查询并合并结果。所以Segment的数量一定程度上会影响查询的效率,所以需要对Segment进行合并,合并的过程就称为Merge,而何时触发Merge由MergePolicy决定
MergeScheduler:当MergePolicy触发Merge后,执行Merge会由MergeScheduler来管理。Merge通常是比较耗CPU和IO的过程,MergeScheduler提供了对Merge过程定制管理的能力
Codec:Codec可以说是Lucene中最核心的部分,定义了Lucene内部所有类型索引的Encoder和Decoder。Lucene在Config这一层将Codec配置化,主要目的是提供对不同版本数据的处理能力。对于Lucene用户来说,这一层的定制需求通常较少,能玩Codec的通常都是顶级玩家了
IndexerThreadPool:管理IndexWriter内部索引线程(DocumentsWriterPerThread)池,这也是Lucene内部定制资源管理的一部分
FlushPolicy:FlushPolicy决定了In-memory buffer何时被flush,默认的实现会根据RAM大小和文档个数来判断Flush的时机,FlushPolicy会在每次文档add/update/delete时调用判定
MaxBufferedDoc:Lucene提供的默认FlushPolicy的实现FlushByRamOrCountsPolicy中允许DocumentsWriterPerThread使用的最大文档数上限,超过则触发Flush
RAMBufferSizeMB:Lucene提供的默认FlushPolicy的实现FlushByRamOrCountsPolicy中允许DocumentsWriterPerThread使用的最大内存上限,超过则触发flush
RAMPerThreadHardLimitMB:除了FlushPolicy能决定Flush外,Lucene还会有一个指标强制限制DocumentsWriterPerThread占用的内存大小,当超过阈值则强制flush
Analyzer:即分词器,这个通常是定制化最多的,特别是针对不同的语言
核心操作
addDocument:比较纯粹的一个API,就是向Lucene内新增一个文档。Lucene内部没有主键索引,所有新增文档都会被认为一个新的文档,分配一个独立的docId
updateDocuments:更新文档,但是和数据库的更新不太一样。数据库的更新是查询后更新,Lucene的更新是查询后删除再新增。流程是先delete by term,后add document。但是这个流程又和直接先调用delete后调用add效果不一样,只有update能够保证在Thread内部删除和新增保证原子性,详细流程在下一章节会细说
deleteDocument:删除文档,支持两种类型删除,by term和by query。在IndexWriter内部这两种删除的流程不太一样,在下一章节再细说
flush:触发强制flush,将所有Thread的In-memory buffer flush成segment文件,这个动作可以清理内存,强制对数据做持久化
prepareCommit/commit/rollback:commit后数据才可被搜索,commit是一个二阶段操作,prepareCommit是二阶段操作的第一个阶段,也可以通过调用commit一步完成,rollback提供了回滚到last commit的操作
maybeMerge/forceMerge:maybeMerge触发一次MergePolicy的判定,而forceMerge则触发一次强制merge
数据路径
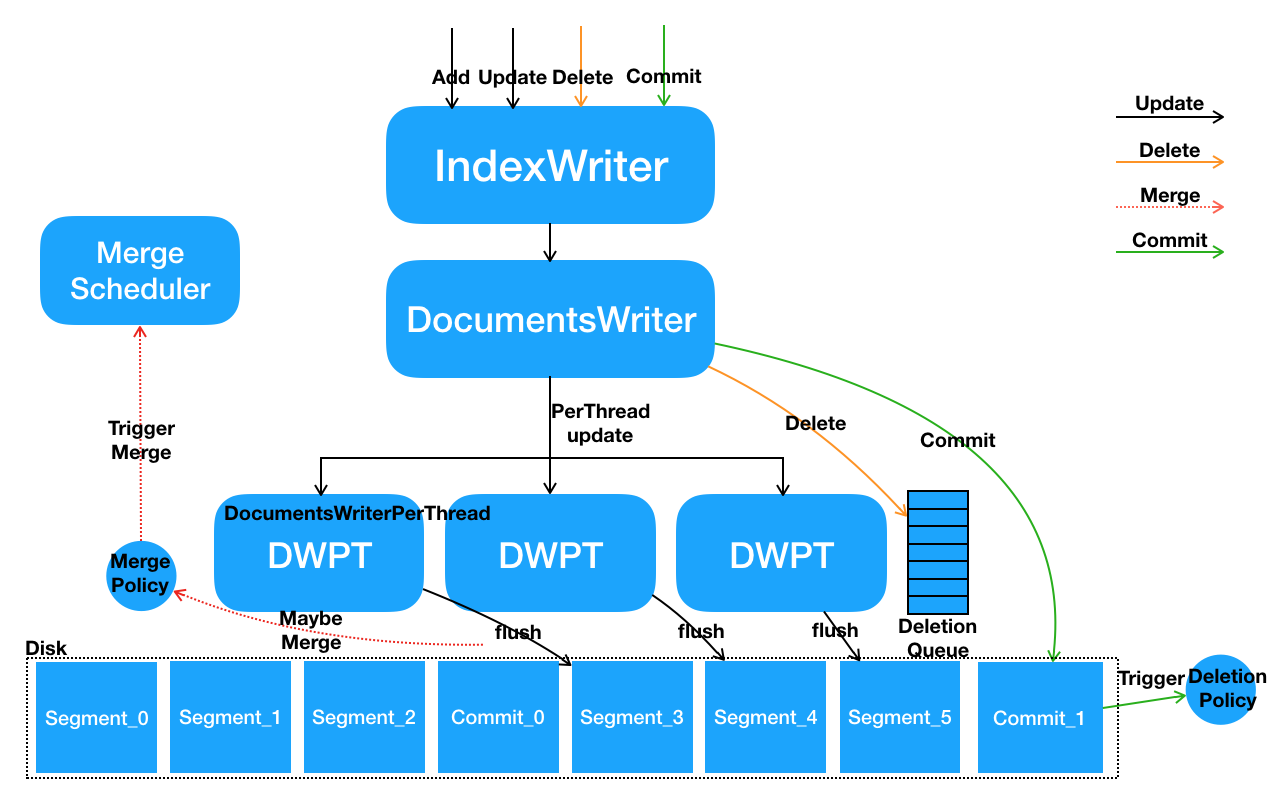
并发模型
空间隔离式的数据写入方式
- 多线程并发调用IndexWriter的写接口,在IndexWriter内部具体请求会由DocumentsWriter来执行。DocumentsWriter内部在处理请求之前,会先根据当前执行操作的Thread来分配
DocumentsWriterPerThread(DWPT) - 每个线程在其独立的DocumentsWriterPerThread空间内部进行数据处理,包括分词、相关性计算、索引构建等
- 数据处理完毕后,在DocumentsWriter层面执行一些后续动作,例如触发FlushPolicy的判定等
只需要对以上第一步和第三步进行加锁。每个DWPT内单独包含一个In-memory buffer,这个buffer最终会flush成不同的独立的segment文件
add & update
updateDocument
- 根据Thread分配DWPT
- 在DWPT内执行delete
- 在DWPT内执行add
delete
在IndexWriter内部会有一个全局的Deletion Queue,称为Global Deletion Queue,而在每个DWPT内部,还会有一个独立的Deletion Queue,称为Pending Updates。DWPT Pending Updates会与Global Deletion Queue进行双向同步,因为文档删除是全局范围的,不应该只发生在DWPT范围内
Segment中有一个特殊的文件叫live docs,内部是一个位图的数据结构,记录了这个Segment内部哪些DocId是存活的,哪些DocId是被删除的。所以删除的过程就是构建live docs标记位图的过程,数据实际上不会被真正删除,只是在live docs里会被标记删除。live docs只影响倒排,所以在live docs里被标记删除的文档没有办法通过倒排索引检索出,但是还能够通过doc id查询到store fields。文档数据最终是会被真正物理删除,这个过程会发生在merge时
flush
flush是将DWPT内In-memory buffer里的数据持久化到文件的过程,flush会在每次新增文档后由FlushPolicy判定自动触发,也可以通过IndexWriter的flush接口手动触发。每个DWPT会flush成一个segment文件,flush完成后这个segment文件是不可被搜索的,只有在commit之后,所有commit之前flush的文件才可被搜索
commit
commit时会触发数据的一次强制flush,commit完成后再此之前flush的数据才可被搜索。commit动作会触发生成一个commit point,commit point是一个文件。Commit point会由IndexDeletionPolicy管理,lucene默认配置的策略只会保留last commit point
merge
merge是对segment文件合并的动作,合并的好处是能够提高查询的效率以及回收一些被删除的文档。Merge会在segment文件flush时触发MergePolicy来判定自动触发,也可通过IndexWriter进行一次force merge
IndexingChain
在IndexWriter内部,indexing chain上索引构建顺序是invert index、store fields、doc values和point values
Codec,每种类型索引的Encoder和Decoder
- BlockTreeTermsWriter:倒排索引对应的Codec,其中倒排表部分使用Lucene50PostingsWriter(Block方式写入倒排链)和Lucene50SkipWriter(对Block的SkipList索引),词典部分则是使用FST(针对倒排表Block级的词典索引)
- CompressingTermVectorsWriter:对应Term vector索引的Writer,底层是压缩Block格式
- CompressingStoredFieldsWriter:对应Store fields索引的Writer,底层是压缩Block格式
- Lucene70DocValuesConsumer:对应Doc values索引的Writer
- Lucene60PointsWriter:对应Point values索引的Writer
Redis 简介
概述
Remote Dictionary Server
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化
数据类型
https://redis.io/docs/manual/data-types/
限制:值的长度限制为512MB,元素大小限制为2^32-1
string
https://redis.io/commands/?group=string incr, decr, incrby append, getrange, setrange setbit, getbit
list
lpush, ltrim, blpop
set
spop, srandmember, sinter
zset
zrange, zrank, zrangebyscore
hash
stream
https://redis.io/docs/manual/data-types/streams/#consumer-groups xadd, xrange, xrevrange, xread, xgroup,
Streams 是一个只追加的数据结构
序号范围扫描,id定位的复杂度O(logN)
# key: mystream
# stream id: * 或手工指定
# * 自动生成<millisecondsTime>-<sequenceNumber>
# sensor-id 1234 temperature 19.8 空格分隔为列表
xadd mystream * sensor-id 1234 temperature 19.8
xadd somestream 0-* baz qux
# 最小id - 和最大id +之间的所有数据
xrange mystream - + count 10
# 时间戳范围
xrange mystream <millisecondsTime_start> <millisecondsTime_end>
# (id1 表示id刚好比id1大的数据,可用于迭代扫描
xrange mystream (id1 + count 10
# 反序
xrevrange + - count 1
监听流
# 非阻塞地从多个流中获取id大于指定id的数据
xread [count 2] streams mystream1 mystream2 id_or_time1 id_or_time2
# block 0 阻塞0ms 即永久阻塞
# $表示最后一条数据
xread block 0 streams mystream $
消费组
# 创建一个消费组,并指定消费偏移量
# $ 最后一条消息 0 最早一条消息
xgroup create mystream mygroup $
# 不存在则创建流
xgroup create newstream mygroup $ mkstream
# > 特殊ID,指到目前为止,消息从未传递给同组的其他消费者,如果指定0之类的真实ID,则表示往后没有被xack的消息
xreadgroup group mygroup consumer_name count 1 streams mystream >
流程
线程模型核心是基于非阻塞的IO多路复用机制
持久化
RDB
把当前内存数据生成快照保存到硬盘
手动触发
手动触发对应save命令,会阻塞当前Redis服务器,直到RDB过程完成为止
自动触发
自动触发对应bgsave命令,Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段
save <seconds> <changes>,表示xx秒内数据修改xx次时自动触发bgsave
- 从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则 自动执行bgsave
AOF
以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的
appendonly yes 开启AOF
appendfilename appendonly.aof AOF文件名
- 所有的写入命令会追加到aof_buf(缓冲区)中
- AOF缓冲区根据对应的策略向硬盘做同步操作(fsync 策略:无fsync、每秒fsync 、每写fsync, 默认每秒)
- 定期对AOF文件进行重写,达到压缩的目的
- 当Redis服务器重启时,加载AOF文件进行数据恢复
AOF重写
- 手动触发:
bgrewriteaof - 自动触发
auto-aof-rewrite-min-size:运行AOF重写时文件最小体积,默认为64MBauto-aof-rewrite-percentage:当前AOF文件空间aof_current_size和上一次重写后AOF文件空间aof_base_size的最小比值
info persistence可查看aof_current_size和aof_base_size,以上两个条件同时满足即触发AOF重写
Redis 缓存
缓存问题
Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃
本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死
缓存穿透
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空
- 布隆过滤器
布隆过滤器(Bloom Filter,简称BF),是一种空间效率高的概率型数据结构,用来检测集合中是否存在特定的元素
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1
当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中(哈希碰撞)
- 返回空对象
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中。为了避免存储过多空对象,通常会给空对象设置一个过期时间
缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库
- 使用互斥锁(mutex key)
让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存
- 热点数据永不过期
针对热点key不设置过期时间,或者把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上
- 均匀过期 设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期
- 双层缓存策略
- 加互斥锁
- 缓存永不过期
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统
缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据
Redis的内存淘汰机制
maxmemory 0,在64位操作系统下最大内存为操作系统剩余内存
淘汰策略
- noeviction 默认策略,对于写请求直接返回错误,不进行淘汰
- allkeys-lru 从所有的key中使用近似LRU算法(最近最少使用)进行淘汰
- volatile-lru 从设置了过期时间的key中使用近似LRU算法进行淘汰
- allkeys-random 从所有的key中随机淘汰
- volatile-random 从设置了过期时间的key中随机淘汰
- volatile-ttl 在设置了过期时间的key中根据key的过期时间进行淘汰,越早过期的越优先被淘汰
- allkeys-lfu 从所有的key中使用近似LFU算法(最少使用频率)进行淘汰
- volatile-lfu 设置了过期时间的key中使用近似LFU算法进行淘汰
缓存更新机制
Cache aside 旁路缓存
读请求:应用首先会判断缓存是否有该数据,缓存命中直接返回数据,缓存未命中即缓存穿透到数据库,从数据库查询数据然后回写到缓存中,最后返回数据给客户端 写请求:首先更新数据库,然后从缓存中删除该数据
更新缓存的时间要远大于数据库,故如果读请求早于写请求读到数据库的旧值,则会更早地把旧值写到缓存中,紧接着,写请求从缓存删除该旧值
- 先更新数据库,再更新缓存:写请求冲突,旧的写请求会在更新缓存时覆盖新的写请求
- 先删缓存,再更新数据库(或先更新数据库,再删除缓存):旧的读请求会在新的写请求删完缓存中的旧值之后,又写入自己读取到的旧值
Read/Write through
将数据库的同步委托给缓存提供程序Cache Provider
Write behind/back
即延迟写入,应用程序更新数据时只更新缓存,Cache Provider每隔一段时间将数据刷新到数据库中
Redis 特性
发布订阅
事件推送
事件类型
__keyspace@db:key_pattern键空间通知(key-space notification)__keyevent@db:ops_type键事件通知(key-event notification)
执行del mykey之后,相当于发送以下事件
publish __keyspace@0__:mykey del
publish __keyevent@0__:del mykey
开启E键事件通知,针对x过期事件(键访问触发检查而删除该键,或者后台查找并删除)
config set notify-keyspace-events Ex
Redis的过期事件发生的时机,是真正删除的时候,而不是在理论上生存时间达到零值时生成