Flink 简介
概述
Apache Flink是一个开源的分布式,高性能,高可用,准确的流处理框架。同时支持实时流(stream)处理和批(batch)处理,其中批数据看做是流数据的一个特例。
在批(batch)处理中,批数据是在时间上有界的数据,需要处理的数据量是确定的。而在流(stream)处理中,流数据是在时间上无界的数据。相对于批数据,流数据增加了一个新的时间维度。流处理和批处理,需要处理的对象都是大数据,需要解决大数据处理的共性问题。
流处理和批处理
CAP定理是大数据处理的基础约束,对一个分布式计算系统,C(Consistency 一致性)、A(Availability 可用性)、P(Partition tolerance 分区容忍性)难以同时满足。
因为大数据处理是在分布式环境下执行的,所以P是默认要满足的,C和A之间需要做出权衡取舍。
对于批处理系统,追求的是C,保证结果的正确性,牺牲了A,因为批处理对延时不敏感,几分钟甚至几小时之内获得计算结果都可以。
对于流处理系统,首先要保证C,用户对数据处理的基本需求,是要获得正确的结果。但是A也不能牺牲,因为流式数据处理天然有实时性的需求,较高的数据延时会严重影响用户体验。受CAP定理的约束,C和A难以兼得,于是在流式处理系统中,问题被定义成:在保证准确性的前提下,尽可能地追求实时性。
Flink设计思想
@startmindmap
'!theme sketchy
'!theme silver
!theme plain
'!include https://unpkg.com/plantuml-style-c4@latest/core.puml
+ Flink
++ Stratosphere 大数据分析引擎
+++ Meteor,定义执行逻辑,一种将算子视为一等公民的DSL
+++ Sopremo,将Meteor脚本编译为PACT模型\n\
(用于编写分布式数据批处理作业)
+++ PACT,将PACT定义的数据模型转换成Nephele Job Graph
+++ Nephele,Job Graph的执行引擎,将Job Graph调度和切分成Task任务,\n\
并提供调度、执行、资源管理、容错管理、I/O服务等功能;
++ Google开源论文提出的DataFlow/Beam编程模型
+++ 对无界、无序的数据源按数据本身的特征进行窗口计算
+++ 窗口、时间域和水位线
++ 分布式异步快照算法Chandy-Lamport
+++ 使用两阶段提交保存一个全局快照
-- 低延迟
-- 高吞吐
-- Exactly-Once数据一致性
@endmindmap
Flink解决方案
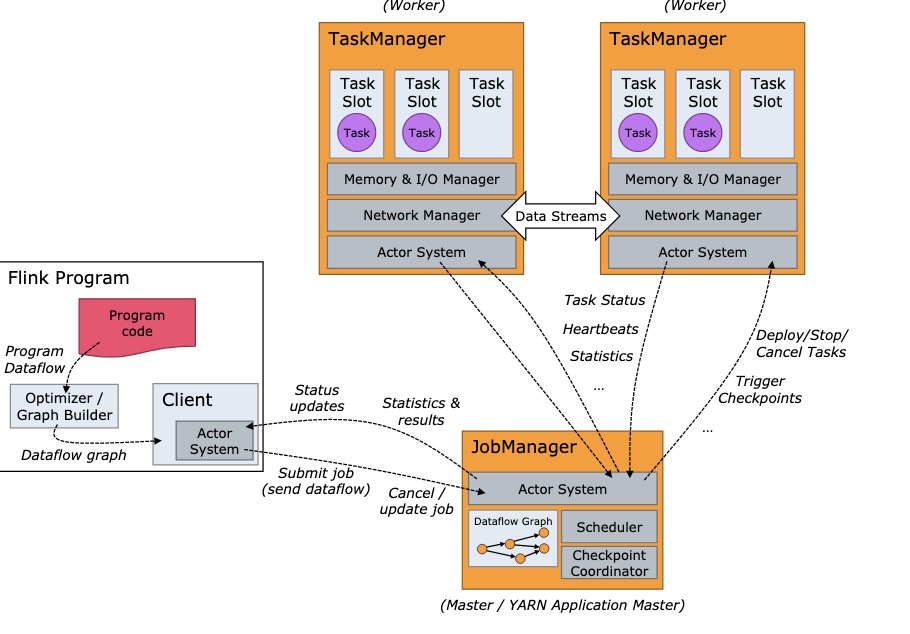
集群架构
Job提交流程
@startuml
!theme mars
'!theme materia
actor "用户" as user
control "客户端" as client
control "JobManager" as job
control "TaskManager" as task
user -> client: 提交Job\n\
(Table SQL或DataStream API Jar等形式)
client --> client: 加载用户提交的任务代码,\n\
解析成StreamGraph并生成任务执行拓扑图JobGraph
note left
flink内部使用Akka框架(Actor System)和Netty
进行通信, 通过发送消息驱动任务的推进。
end note
client -> job: 将拓扑图JobGraph提交给JobManager
job --> job: 基于任务执行拓扑图JobGraph,\n\
生成相应的物理执行计划ExecutionGraph
job -> task: 将执行计划ExecutionGraph发送给TaskManager执行\n\
(启用Task)
@enduml
JobManager(master)
Flink 系统的管理节点,全局只有一个,管理所有的 TaskManager,并决策用户任务在哪些 Taskmanager 执行。同时在运行过程中,会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
TaskManager (slave)
Flink 系统的业务执行节点,执行具体的用户任务,提供了内存管理、IO管理、网络管理功能。每个TaskManger上运行一个jvm进程。每个TaskManger拥有多个TaskSlot,而每个TaskSlot运行一个线程。Flink允许同一个任务的多个子任务,并且会尽量将多个子任务放到一个slot中执行。
时间
流数据相对于批数据,增加了一个时间维度。时间可以有以下3中表征方式:
Event Time表征事件发生的时间,是事件本身的固有属性,由事件生产者自行定义,默认为空,即Long.MIN_VALUE。可以用于解决消息乱序的时候一致性问题Ingestion Time事件流入Flink source operator的时间。Processing Time事件被Flink算子处理的时间。
@startuml
!theme materia
actor "事件生产者" as producer
note bottom
事件时间
end note
database "消息队列" as mq
frame "Flink" {
collections "source" as source
note bottom
摄入时间
end note
node "TaskSolt 1" as solt1
node "TaskSolt 2" as solt2
note bottom
处理时间
end note
}
producer -right-> mq
mq -right-> source
source -right-> solt1
solt1 -right-> solt2
@enduml
窗口 Window
由于流数据是时间上是无限的,那么可以将数据流在逻辑上做切分,分成一个个的窗口,在每一个窗口中进行数据计算。(这里也可以逐条处理)
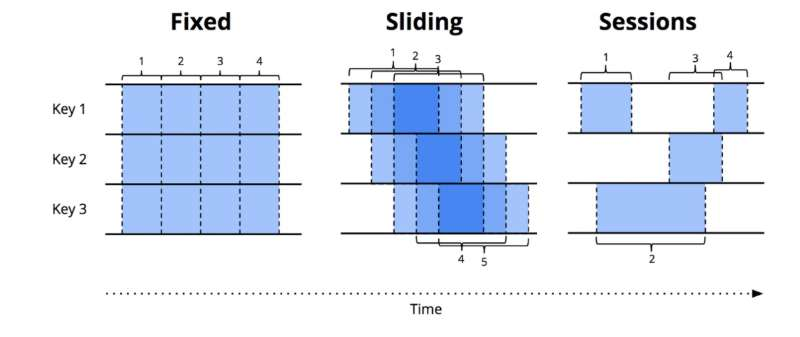
Flink 支持以下几种窗口类型:
Tumbling Window: 固定时间间隔的窗口。比如统计每分钟整点内的网站访问次数。Sliding Window: 滑动窗口,按一定的滑动尺寸和窗口大小进行计算。比如统计最近1分钟的网站访问次数,每隔10秒钟输出一次。那么窗口大小为1min,每次滑动前进10s。Sessions Window: 会话窗口。按会话维度进行统计。比如针对每个访问网站的用户建立会话,并且设定会话窗口超时阈值,假设1分钟。如果在最近1分钟之内,用户执行了操作,则将这些操作在同一个会话窗口中进行计算。Custom Window: 自定义窗口,继承WindowAssigner
触发器 Trigger
Flink使用Trigger(触发器)来决定何时输出计算结果。
Repeated update triggers: 这个是最简单的形式,按固定的频率输出计算结果。Completeness triggers: 等到数据完整之后,输出计算结果。如何定义数据完整性呢?这就需要引入Watermark的概念。WaterMark是表征何时数据已经完整的标识。带有时间戳为X的waterMark表示,event time在X之前的数据,已经到齐了。Early/On-Time/Late Triggers: 这个是综合以上两种Trigger,对于早到、准时及迟到的数据分别输出计算结果。实际实现的时候,不会无限制地等待迟到的数据,会加上迟到时间的限制,丢弃超过限制的数据。
水位线 Watermark
Perfect watermarks: 确定性watermark。如果能够准确的评估出数据延迟时间的最大值,就可以使用 perfect watermark。Heuristic watermarks: 启发式watermark。在数据处理的过程中,Flink基于观察到的数据延时,不断的动态调整Watermark的值。适用于数据延时有较大波动的场景。
水位线提供了一种结果可信度和延时之间的妥协。激进的水位线设置可以保证低延迟,但结果的准确性不够;如果水位线设置的过于宽松,计算的结果准确性会很高,但可能会增加流处理程序不必要的延时。在追求数据完整性的过程中,正确性和低延迟不可兼得。我们需要在保证正确性的前提下,尽量减少延迟。如果条件允许的话,最好使用Perfect watermark。
Job 执行流程
每个Job 定义的执行流程都由由以下三个部分组成:
- Source(数据源):负责获取输入数据。
- Transformation(数据处理):对数据进行处理加工,通常对应着多个算子。
- Sink(数据汇):负责输出数据。
Flink程序执行时,由流和转换操作映射到streaming dataflows,每个数据流有一个或多个 source,有一个或多个sink,这个数据流最终形成一个DAG(有向无环图)。
@startuml
!theme mars
database "source" as source
node "transformations" as transformations
database "sink" as sink
source -> transformations
transformations -> sink
@enduml
变换 Transformation
map:输入一个元素,然后返回一个元素flatmap: 输入一个元素,可以返回零个,一个或者多个元素filter: 对流进行过滤,符合条件的数据会被留下keyBy: 根据指定的key进行分组,类似于SQL中的group byreduce: 对数据进行聚合操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值aggregations:sum,min,max等union:合并多个流,新得到的流会包含被合并的流中的所有数据split:根据规则把一个数据流切分为多个流,类似于Java Stream API中的partition
状态 State
Flink中的持久化模型,实现为RocksDB本地文件+异步HDFS持久化,也可使用基于Niagara的分布式存储。
State分为两类:
KeyedState:这里面的key是我们在SQL语句中对应的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段组成的Row的字节数组,每一个key都有一个属于自己的State,key与key之间的State是不可见的;OperatorState:Blink内部的Source Connector的实现中就会用OperatorState来记录source数据读取的offset。
双流inner join场景
@startuml
!theme mars
database "左表 stream" as left
database "右表 stream" as right
queue "Join stream" as join
database "State状态后端" as state
queue "下游 stream" as output
left -> join: 先流入 1,2,3 三个事件
join -> state: 存入 1,2,3
right -> join: 流入 a 一个事件
join -> state: 存入 a
join -> join: 将 a 与左表已经到达的事件 1,2,3 进行join
join -> output: 将join的结果输出到下游
left -> join: 流入 4 一个事件
join -> join: 将 4 与右表已经到达的事件 a 进行join
join -> output: 将join的结果输出到下游
@enduml
定时器服务 TimerService
Flink开箱即用的提供了一套定时触发API,一般在KeyedProcessFunction中使用
void registerEventTimeTimer(long time);注册定时器void deleteEventTimeTimer(long time);删除定时器void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out)自定义回调函数
API示例
DataStream示例代码
public class StreamGraphSimpleDemo {
public static void main(String[] args) throws Exception {
// 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
// 添加输入源 [2, 3, 5, 7, 11]
DataStream<Integer> source1 = env.addSource(new Beep<>(
Arrays.asList(2, 3, 5, 7, 11), 1000L, 10_000L),
"source1", TypeInformation.of(Integer.class));
// 添加另一个输入源 [1.0, 2.0, 3.0, 4.0, 5.0]
DataStream<Double> source2 = env.addSource(new Beep<>(
Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0), 1000L, 10_000L),
"source2", TypeInformation.of(Double.class));
// 双流join [4, 9, 25]
DataStream<Integer> ds1 = source1.join(source2)
// source1 join source2 on source1.a == source2.b
.where(a -> a).equalTo(Double::intValue)
// 开窗,滑动窗口,窗口大小为3s,每次前进1s
.window(SlidingEventTimeWindows.of(Time.seconds(3), Time.seconds(1)))
// 纵向合并
.apply((a, b) -> a * b.intValue(), TypeInformation.of(Integer.class));
// 消息变换,一到一映射 [3, 8, 24]
DataStream<Long> ds2 = ds1
.map(value -> value - 1L);
// 消息变换,一到多映射 [3, 3, 8, 8, 24, 24]
DataStream<Integer> ds3 = ds2
.flatMap(((value, out) -> {
out.collect(value.intValue());
out.collect(value.intValue());
}));
// 分组,类似于SQL中的group by [(3, 3), (8, 8, 24, 24)]
DataStream<String> ds4 = ds3
.keyBy(value -> value % 2 == 0)
// 使用 ProcessFunction 处理每条消息 [-3, -3, +8, +8, +24, +24]
// 与map等算子的区别,在于 ProcessFunction
// 可以访问时间戳,watermark和定时器等
.process(new KeyedProcessFunction<Boolean, Integer, String>() {
@Override
public void processElement(Integer value,
KeyedProcessFunction<Boolean, Integer, String>.Context ctx,
Collector<String> out) throws Exception {
Boolean key = ctx.getCurrentKey();
String sign = key ? "+" : "-";
out.collect(sign + value);
}
});
// 使用 PrintSinkFunction 进行sink输出,即输出到控制台
ds4.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
log.info("sink to console: {}", value);
}
}).name("sink");
env.execute("StreamGraphDemo");
}
@RequiredArgsConstructor
public static class Beep<T> extends RichSourceFunction<T> {
final List<T> list;
final long elementIntervalMs;
final long listIntervalMs;
volatile boolean flag = true;
@Override
public void run(SourceContext<T> ctx) throws Exception {
while (flag) {
for (T element : list) {
ctx.collectWithTimestamp(element, System.currentTimeMillis());
Thread.sleep(elementIntervalMs);
}
ctx.markAsTemporarilyIdle();
Thread.sleep(listIntervalMs);
}
}
@Override
public void cancel() {
flag = false;
}
}
}
代码和DAG的对照
@startuml
!theme mars
queue "消息队列1" as mq1
queue "消息队列2" as mq2
collections "source1" as source1
note top
var env = StreamExecutionEnvironment.getExecutionEnvironment();
SourceFunction<Integer> sourceFunction1 = ...; // 输入源
env.addSource(sourceFunction1); // 添加输入源
end note
collections "source2" as source2
note right
// 另一个输入源
SourceFunction<Double> sourceFunction2 = ...;
// 添加另一个输入源
env.addSource(sourceFunction2);
end note
mq1 -right-> source1
mq2 -down-> source2
node "双流join" as join
note right
DataStream<Integer> ds1 = source1.join(source2)
// on 条件
.where(a -> a).equalTo(Double::intValue)
// 开窗,滑动窗口,窗口大小为3s,每次前进1s
.window(SlidingEventTimeWindows.of(Time.seconds(3), Time.seconds(1)))
// 纵向合并
.apply((a, b) -> a * b.intValue(), TypeInformation.of(Integer.class));
end note
source1 -down-> join
source2 -down-> join
node "Map" as map
note left
DataStream<Long> ds2 = ds1
.map(value -> value - 1L);
end note
join -down-> map
node "FlatMap" as flatMap
note right
DataStream<Integer> ds3 = ds2
.flatMap(((value, out) -> {
out.collect(value.intValue());
out.collect(value.intValue());
}));
end note
map -down-> flatMap
node "KeyedProcess" as keyedProcess
note left
KeyedProcessFunction<K, I, O> keyedProcessFunction = ... ;
DataStream<String> ds4 = ds3
.keyBy(value -> value % 2 == 0)
// 使用 ProcessFunction 处理每条分完组之后的事件
// 与map等算子的区别,在于 ProcessFunction
// 可以访问时间戳,watermark和定时器等
.process(keyedProcessFunction);
end note
flatMap -down-> keyedProcess
collections "sink" as sink
note right
SinkFunction<String> sinkFunction = ...; // sink输出
ds4.addSink(sinkFunction); // 添加sink输出
end note
keyedProcess -down-> sink
@enduml
StreamGraph拓扑图
@startuml
!theme mars
database "Source: source1" as source1
database "Source: source2" as source2
cloud "Map-3" as map1
cloud "Map-4" as map2
node "Window" as win
cloud "Map-8" as map3
cloud "Flat Map" as flatMap
cloud "KeyedProcess" as KeyedProcess
database "Sink: sink" as sink
source1 --> map1: Source: source1_Map-3_0_FORWARD
source2 --> map2: Source: source2_Map-4_0_FORWARD
map1 --> win: Map-3_Window(SlidingEventTimeWindows(3000, 1000), \n\
EventTimeTrigger, \nCoGroupWindowFunction)-7_0_HASH
map2 --> win: Map-4_Window(SlidingEventTimeWindows(3000, 1000), \n\
EventTimeTrigger, \nCoGroupWindowFunction)-7_0_HASH
win --> map3: Window(SlidingEventTimeWindows(3000, 1000),\n\
EventTimeTrigger, \nCoGroupWindowFunction)-7_Map-8_0_FORWARD
map3 --> flatMap: Map-8_Flat Map-9_0_FORWARD
flatMap --> KeyedProcess: Flat Map-9_KeyedProcess-11_0_HASH
KeyedProcess --> sink: KeyedProcess-11_Sink: sink-12_0_FORWARD
@enduml
Flink SQL示例
-- source
-- 骑手轨迹
create table knight_active_trace_kafka_source
(
id varchar
,target_type varchar
,target_id varchar
,longitude varchar
,latitude varchar
,tracked_at varchar
,created_at varchar
,updated_at timestamp
-- 该watermarker5秒之前的数据丢弃
,watermark wk for updated_at as withOffset(updated_at, 5000)
)with(
type='kafka'
,topic='knight_active_trace'
);
-- transformations
create view knight_active_trace_last as
select
target_id as delivery_id,
last_value(date_format(updated_at, 'yyyy-MM-dd HH:mm:ss')) as trace_time
from
knight_active_trace_kafka_source
where
target_type = '2' -- 众包
group by
-- 设置滚动窗口为5分钟
tumble(updated_at, interval '5' minute), target_id
-- sink
insert into result_test
select xxx from xxx;
;
Flink 原理
流量控制
基于Credit的反压机制
下游的InputChannel从上游的ResultPartition接收数据的时候,会基于当前已经缓存的数据量,以及可申请到的LocalBufferPool与NetworkBufferPool,计算出一个Credit值返回给上游。上游基于Credit的值,来决定发送多少数据。Credit就像信用卡额度一样,不能超支
当下游发生数据拥塞时,Credit减少值为0,于是上游停止数据发送。拥塞压力不断向上游传导,形成反压
系统容错
流计算容错一致性保证有三种,分别是:
- Exactly-once,是指每条 event 会且只会对 state 产生一次影响,这里的“一次”并非端到端的严格一次,而是指在 Flink 内部只处理一次,不包括 source和 sink 的处理
- At-least-once,是指每条 event 会对 state 产生最少一次影响,也就是存在重复处理的可能
- At-most-once,是指每条 event 会对 state 产生最多一次影响,就是状态可能会在出错时丢失
Checkpointing检查点
Flink会在流上定期产生一个barrier(屏障)。barrier 是一个轻量的,用于标记stream顺序的数据结构。barrier被插入到数据流中,作为数据流的一部分和数据一起向下流动,过程如下:
- barrier 由source节点发出
- barrier会将流上event切分到不同的checkpoint中
- 汇聚到当前节点的多流的barrier要对齐(At least once不需要对齐)
- barrier对齐之后会进行Checkpointing,生成snapshot,快照保存到StateBackend中
- 完成snapshot之后向下游发出barrier,继续直到Sink节点
Flink 调优
Group Aggregate
开启 MicroBatch/MiniBatch (牺牲延迟以提升吞吐)
缓存一定的数据后再触发处理,以减少对 state 的访问从而显著提升吞吐,以及减少输出数据量
MiniBatch主要依靠在每个 task 上注册的 timer 线程来触发微批,会有一定的线程调度开销。MicroBatch 是 MiniBatch 的升级版,主要基于事件消息来触发微批,事件消息会按用户指定的时间间隔在源头插入。MicroBatch 在攒批效率、反压表现、吞吐和延迟性能上都要胜于MiniBatch
开启 LocalGlobal (解决常见数据热点问题)
适用于提升如 SUM, COUNT, MAX, MIN, AVG 等普通 agg 上的性能,以及解决这些场景下的数据热点问题
将原先的 Aggregate 分成Local+Global 两阶段聚合。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator),第二阶段再将收到的 Accumulator merge起来,得到最终的结果(globalAgg)
TopN
分组 TopN:根据不同的分组进行排序,计算出每个分组的一个排行榜
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]
最优的流式 TopN 的计算只需要维护一个 N 元素大小的小根堆,每当有数据到达时,只需要与堆顶元素比较,如果比堆顶元素还小,则直接丢弃;如果比堆顶元素大,则更新小根堆,并输出更新后的排行榜
TopN 算子的实现上主要有两个数据结构,一个是 TreeMap,另一个是 MapState。TreeMap作为小根堆,有序地存放了排名前 N 的元素。MapState用于持久化TreeMap
嵌套 TopN 解决热点问题
数据倾斜(最坏的情况是全局 TopN,所有数据都倾斜到一个节点)
两层 TopN。在原先的 TopN 前面,再加一层 TopN,用于分散热点
CREATE VIEW tmp_topn AS
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY HASH_CODE(shop_id)%128 ORDER BY sales DESC) AS rownum
FROM shop_sales)
WHERE rownum <= 10
SELECT *
FROM (
SELECT shop_id, shop_name, sales,
ROW_NUMBER() OVER (ORDER BY sales DESC) AS rownum
FROM tmp_topn)
WHERE rownum <= 10